 供需大厅
供需大厅
 登录/注册
登录/注册 供应商登录
供应商登录










荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。
欢迎来到荣格工业资源网!

供需大厅

登录/注册
公众号

更多资讯,关注微信公众号
小秘书

更多资讯,关注荣格小秘书
邮箱
您可以联系我们 info@ringiertrade.com

电话
您可以拨打热线
+86-21 6289-5533 x 269
建议或意见
+86-20 2885 5256
顶部

荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。



摘要:为了实现番茄含糖量无损在线检测,本文提出了一种基于透射光谱的番茄含糖量检测方法CARS-RFR。首先,通过采集装置对番茄进行光谱数据采集与有效区域提取;然后,采用Savitzky-Golay平滑处理和标准正态变量变化两种数据预处理方法,获取番茄有效透视光谱数据;接着,提出了基于竞争自适应加权法(CARS)提取关键光谱特征,构成番茄含糖量预测模型的输入;最后,构建了基于随机森林回归(RFR)模型,实现了对番茄含糖量的无损检测。实验结果表明,所提出的CARS-RFR方法在测试集上预测的番茄含糖量与真实值的相关系数R高达到0.774,均方根误差RMSE为0.281,优于其他对比模型。所提出的CARS-RFR在线无损检测方法,为番茄品质智能检测分级提供了技术支持,也为农产品无损检测提供了新的思路。
引言
番茄是一种全球性重要农作物,广泛应用于食品加工和饮食,它含有丰富的维生素、矿物质和抗氧化剂[1],对人体健康有着积极影响。此外,番茄也是重要的工业原料,它是许多食品和调味品的原料之一,对于食品工业来说有着重要作用。
对于番茄而言,进行无损化的检测与果实分级,是提高番茄经济效益的重要手段。在分选过程中,对于番茄表面进行检测,将有虫害和表皮受伤的果子进行提前剔除,能够有效减轻病虫害的传播,也可让消费者在消费时有选择的选择不同级别的番茄果实。然而,对于番茄内部品质和口感则难以通过传统人工分拣实现。
光谱技术能够实现对果蔬内部质量的检测。Baohua Tan等人[2]利用近红外漫反射检测技术,建立基于BP神经网络的樱桃番茄含糖量预测模型,实验验证该模型预测平均绝对偏差为0.5711。Ioannis S. Minas等人[3]基于近红外光谱检测技术,设计了一个用于评估桃子内部品质和成熟度的多元预测模型,对于桃子的无损检测具有重要意义。Razieh Pourdarbani等人[4]利用400~1000nm波长范围的可见光和短波近红外光谱对红富士样本进行无损检测建模,对果实的硬度、酸度和淀粉含量等不同理化特性能够构建回归预测模型进行无损评价。
因此,本研究以番茄作为研究对象,旨在实现对番茄内部品质指标的检测并以此进行品质分级。在本实验中构建番茄含糖量预测数据集,为后续实验提供保障。使用含糖量作为番茄内部品质检测的主要分级依据指标,构建基于光谱数据的番茄含糖量预测模型实现含糖量精确预测,进而为工业化番茄品质智能检测分选设备的研制提供技术支持。
1 数据采集与处理
1.1 数据采集与提取
利用光谱数据进行番茄含糖量预测,其原理基础在于番茄中的糖类对特定波段的光具有特征性吸收,这种吸收现象主要源于番茄糖分的含氢基团内的C-H、O-H等化学键在受光激发后的振动及跃迁行为[2]。不同含糖量的番茄由于内部糖分、水分等成分间的差异,会使其光谱数据在特定波段出现差异,通过获取番茄透射光谱数据并结合相应糖度值,可以建立模型实现对番茄含糖量的有效预测。

图 1. 番茄投射光谱伪 RGB 图
本研究使用自主设计搭建的番茄光谱采集系统,主要包含VSPEX10光谱相机、1KW的卤素灯光源以及传送机构。光谱相机可采集的波段为400nm-1000nm,单次线阵采集输出数据为1×2048×224,包含224个谱段信息。采集时10个番茄为1组,均匀摆放在传送带上,以组为单位进行光谱数据采集。图1为1组番茄采集的透射光谱数据伪RGB图,其中黑色区域为目标番茄,上方光带区域为卤素灯光束聚集区,下方偏绿色的为果拖传输带。按照先入先出顺序,番茄的序号从右到左依次为1、2、3、……、9、10。
为了提高不同光照条件下光谱数据的稳定性,对采集的光谱数据进行黑白场校正,计算公式为: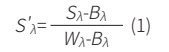
其中,S'λ为经过黑白场校正之后的光谱透射率;Sλ为实际测量下的光谱透射率;Bλ为黑场条件(盖上镜头盖保持镜头密闭不透光)下采集到的光谱透射率;Wλ为白场条件(光源直射到镜头上且光源与镜头之间无遮挡)下采集到的光谱透射率。
由于番茄个体较小,番茄透射伪彩色图1中存在拉伸现象,也包含很多无用背景数据。因此,采用掩膜提取法,提取图1上方光带范围内的黑色区域作为番茄透射光谱采集的目标区域,以保障数据的稳定性和可靠性。
掩膜提取法即借助生成的伪彩色图绘制指定目标区域的二值化掩膜,序号为1的番茄二值化掩膜如图2所示,之后根据光谱相机保存的hdr头文件、原始光谱数据以及生成的二值化掩膜即可进行目标区域光谱数据提取。提取之后对单一波长上的光谱透射率数据进行求均值,即: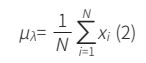
其中,λ表示波长;N为目标区域像素总数;xi表示第i个像素在波长 λ上的光谱投射率;μλ表示目标番茄区域在 λ波长上的平均光谱透射率。

图2. 序号为1的番茄二值化掩膜示意图
经过上述处理,共采集了140个番茄样本光谱数据。对采集的光谱投射率进行均值提取汇总后,获得如图3所示样本数据。

图3. 番茄样本数据集透射率曲线示意图
1.2 数据预处理方法
图3中可明显看出原始数据集存在数据噪声,尤其在光谱曲线的高频部分。这些噪点体现为数据中的随机波动,同时存在一些局部突出的尖峰和低谷,其形成原因可能是由采集过程中存在的机械振动或番茄及光源的波动引起的。这些不规则的波动会影响光谱数据的平滑性和整体趋势,因此需对数据进行预处理,在去除噪点毛刺的情况下尽可能保留原有光谱的有效信息。
针对原始光谱数据存在的问题,选用Savitzky-Golay平滑处理技术[5]结合标准正态变量变换[6](SNV)对原始光谱数据进行数据处理。
1.2.1 Savitzky-Golay平滑处理技术
Savitzky-Golay(SG)平滑处理是常见的平滑滤波技术[7],其是一种基于局部多项式最小二乘法拟合的平滑方法,适用于数据中存在高频噪声和毛刺的情况。SG平滑处理的基本思想为:在数据点的邻域内,用一个多项式对数据进行拟合;通过最小二乘法确定多项式系数,使拟合误差最小;使用拟合多项式在中心点的值作为平滑后的输出值,即:
其中,yi SG表示平滑后的数据点,即对原始数据点yi 平滑处理之后的结果;yi +k表示原始数据点的具体值;k是索引偏移量,k∈[-m,m],表示从中心点yi 开始的邻近数据点;bk是SG滤波器的卷积系数(权重系数),是通过多项式拟合和最小二乘法计算得到的。
SG对于原始光谱数据通过多项式拟合来平滑曲线,平滑结果如图4所示,明显去除了光谱数据中的噪声和毛刺,同时保留了光谱有效信息和整体趋势。
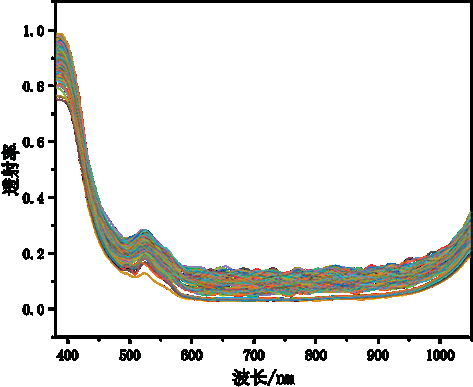
图4. Savitzky-Golay平滑后的番茄样本数据集透射率曲线示意图
1.2.2 标准正态变量变换
标准正态变量变换(Standard Normal Variate,SNV)是一种常用于光谱数据预处理[8]的标准化方法,旨在消除光谱数据中的散射效应和实验仪器误差等偏差。其基本思想为:通过对每条光谱进行中心化处理以消除基线漂移;借助标准化处理减少因为样本表面散射引起的光谱数据差异;借助标准化使得处理后的数据具有统一尺度,增强了光谱数据的可比性。SNV计算公式为: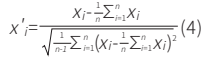
其中,x'i表示标准化后第i个谱段的值;xi表示第i个谱段的原始光谱数据值; ![]() 表示光谱数据均值;
表示光谱数据均值;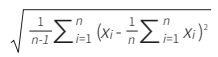 表示光谱数据的样本标准差;n表示光谱数据包含的谱段个数。
表示光谱数据的样本标准差;n表示光谱数据包含的谱段个数。
SNV方法通过对每个数据点进行标准化处理,使其均值为0,标准差为1,进而消除系统偏差带来的影响,保持光谱数据的可比性。图4光谱数据进过SNV处理后如图5所示,进一步消除了噪点和杂散光影响,提高数据的可靠性和稳定性,有助于保障后续番茄含糖量预测模型的稳定性和性能。
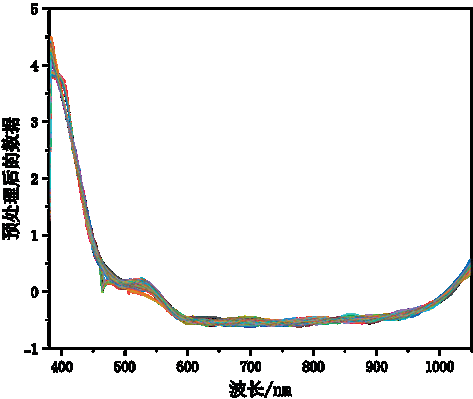
图5. SG-SNV处理后番茄样本数据集光谱特性曲线示意图
1.3 数据集构建
对采集的140个番茄样本进行数据集划分,按照4:1的比例划分为训练集和测试集,得到训练集样本数量为112个,测试集样本数量为28个。为保障番茄含糖量预测模型的精准,番茄样本在经过光谱数据采集模块之后就立即使用番茄糖度理化信息采集装置——数显折光仪进行番茄含糖量测量,依次对同个番茄采集多次糖度数据后取均值作为最终含糖量数据,减少数据测量误差。番茄含糖量检测统计数据如表1所示。
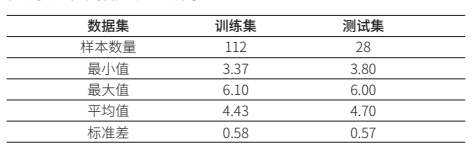
表 1. 番茄含糖量统计数据表
2 番茄含糖量预测模型CARS-RFR
为了实现对番茄含糖量的无损检测,提出了基于光谱的番茄含糖量预测模型CARS-RFR。首先,采用竞争自适应加权算法(Competitive Adaptive Reweighted Sampling,CARS)对处理后的番茄透射光谱数据进行特征谱段筛选,确定主要特征谱段集合;以此基础上,引入随机森林回归(Random Forest Regression,RFR)建立含糖量预测模型,实现对番茄含糖量的精准预测。
2.1 CARS特征谱段筛选
在本研究中,所采集的光谱数据包含224个谱段,实际波长范围覆盖从380nm到1050nm。其中存在大量冗余信息,这不仅会对模型效率造成影响,还会降低模型精度。尤其在面向工业应用场景中[9],效率是不可忽略的关键因素。在本研究所面向的工业化番茄品质智能检测分级装置研发中,光谱数据采集模块工作效率是制约整体运行效率的关键,因此为了降低计算复杂度,提高运行效率,需要对谱段进行筛选,确定合适的谱段组合至关重要。
根据本研究所进行实验的实际情况综合考虑,选择竞争自适应加权算法[10](CARS)进行特征谱段的筛选。CARS是一种启发式算法,通过模拟“适者生存”的竞争机制来动态加权光谱谱段,进而选择最具有区分性的特征谱段,以此减少冗余谱段,提高模型的效率。
其核心思想是通过多次迭代逐步筛选出最优的谱段子集,该方法初始是在光谱谱段范围内随机抽取一个小规模谱段作为初始谱段集,之后使用偏最小二乘法回归(Partial Least Squares Regression, PLSR)建立基于初始谱段集的回归模型并计算每个谱段的权重,将权重更大的谱段保留至新的谱段集用来建立新的PLSR模型,逐步淘汰权重较低的谱段。多次迭代后逐步缩小波段范围,筛选出对模型贡献度最高的谱段集。
CARS算法的核心运算可使用公式(5)和公式(6)进行描述,![]() 分别代表两个核心机制:特征选择的加权概率和权重更新。
分别代表两个核心机制:特征选择的加权概率和权重更新。
其中,P(fi)表示第i个特征谱段被选中的概率;wi表示第i个特征谱段的权重;![]() 表示当前特征谱段集的所有谱段权重之和。
表示当前特征谱段集的所有谱段权重之和。
![]()
其中,wi(t+1)表示第i个特征谱段在第t+1次迭代计算中的更新权重;wi(t)表示第i个特征谱段在第t次迭代计算中的权重;λ表示学习速率参数;E(fi )是第i个特征谱段的误差度量,即为模型的误差性能指标。
通过多次迭代上述过程,CARS算法能够逐步确定贡献度更高的特征谱段集合,与此同时还在进一步精简特征谱段集合,实现效率和性能相统一。
2.2 RFR预测算法
随机森林回归(Random Forest Regression,RFR)[11]是一种集成学习方法,借助构建多个决策树并对其预测结果进行综合,提高模型的准确度和稳定性,利用了多个决策树的集成优势,在处理高维数据和非线性关系之间表现出色。其工作流程如下:
(a)数据采样:从训练集中使用Bootstrap方法进行抽样,生成多个不同训练子集,用来构建多个决策树(Decision Tree, DT)模型,每个训练子集都对应一个决策树模型;
(b)随机特征选择:在决策树进行节点分裂时,随机从特征集中选取一部分特征进行分裂;
(c)训练决策树模型:每个决策树模型的训练都是一个典型训练过程,在其中使用CART(Classification And Regression Trees,CART)[12]算法构建回归树模型,递归地选择最佳分裂特征和分裂点,以实现将数据集划分为不纯度最小的子集;
(d)最终预测:随机森林通过对所有决策树的预测结果进行平均来得到最终回归预测值。
针对番茄含糖量预测问题,构建的番茄含糖量预测模型CARS-RFR,基于预处理过后的光谱数据和含糖量数据,建立CARS-RFR模型时,相应参数设置如表2所示。
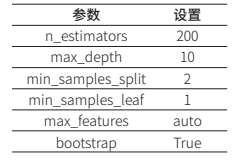
表2. CARS-RFR模型相关参数示意表
3 实验结果与分析
3.1 评价指标
为了评估所提出的番茄内部含糖量预测模型性能,使用均方根误差(RMSE)和相关系数(R)进行模型性能评估,即:
其中,yi 表示第i个样本的真实值;yi 表示第i个样本的模型预测值;n表示样本总数。
其中,xi 和yi 是第 i个数据点的两个对应变量值;x和y表示变量x和 y 的均值;n表示样本总数。
3.2 实验结果
3.2.1 特征谱段集合筛选结果
在对经过数据预处理之后的番茄内部透射光谱使用CARS和随机蛙跳算法进行特征谱段集合筛选。考虑到随机筛选的偶发性,选取多次重复筛选之后效果最好的子集作为目标特征谱段集合,判断指标采取测试集上的均方根误差(RMSEP)对特征谱段集合进行性能评判。对于番茄内部含糖量预测问题,应用两种方法筛选的谱段集合如表3所示。可见,CARS所提取的谱段作为模型的输入优于随机蛙跳算法。
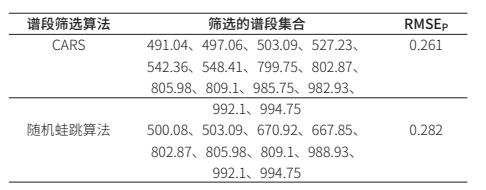
表 3. 特征谱段集合筛选示意表
3.2.2 对比实验结果
为了进一步对比分析特征提取和预测方法性能,对数据预处理之后的番茄透射光谱数据进行番茄含糖量预测模型构建,实验结果如表4所示。可见,特征谱段筛选方法有益于提升模型性能,在去除大量冗余信息之后依旧能够维持模型性能优越,实现了在维持性能的前提下提升整体效率。对比多组实验结果,可见CARS对于特征谱段筛选具有良好助益。随机蛙跳算法(RF)也带来了较好的模型拟合能力,但其对于模型性能提升所提供的帮助略微逊色。整体表现最好的是CARS-RFR模型,其在训练集和测试集上的相关系数R分别达到0.792和0.774,均方根误差RMSE分别为0.278和0.281,相较于其他模型,该模型的综合性能表现最佳。同时也可看出,特征谱段筛选也会带来坏的影响,由于谱段数减少,其模型性能会出现偶发性下降,特征谱段筛选方法在寻找高权重特征谱段的同时也丢弃了一些低权重谱段,会对模型性能造成一点影响。但相比之下,精简特征谱段所产生的积极效益显著高于其消极影响,可以为整体效率提升提供有效帮助,解决了光谱数据采集模块影响整体运行效率短板问题。
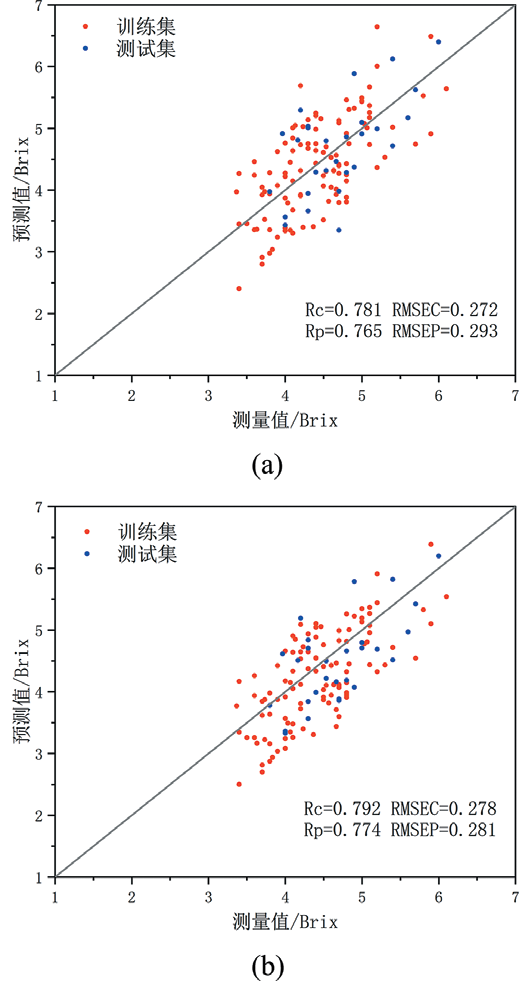
图6. 含糖量预测结果示意图(其中(a)为CARS-PLSR,(b)为CARS-RFR)
综上所述,使用Savitzky-Golay平滑处理技术和标准正态变量变化技术对采集到的光谱透射数据进行数据预处理,之后建立番茄内部含糖量预测模型CARS-RFR具有可行性,符合实验需求。

表4. 实验结果对比表
将两组预测模型的番茄含糖量预测结果绘制散点图,如图6所示。可见,含糖量预测结果相比较而言,所构建的番茄内部含糖量预测模型CARS-RFR整体性能表现更优异。
4 总结
本文提出了一种基于光谱的番茄含糖量无损检测方法CARS-RFR。首先,通过数据采集、数据提取、数据校正以及Savitzky-Golay平滑处理技术和标准正态变量变化两种数据预处理方法,获取番茄含糖量光谱数据;接着,通过CARS提取关键光谱特征,输入构建的RFR预测模型,实现对番茄含糖量的准确估计。实验结果表明,所提出的CARS-RFR在训练集和测试集上的相关系数R分别达到0.792和0.774,均方根误差RMSE分别为0.278和0.281,优于对比模型。CARS-RFR在线无损检测方法,满足实际生产需要,为工业化番茄品质智能检测分级设备的研制提供技术支持。
参考资料:
[1] Md Yousuf Ali, Abu Ali Ibn Sina, Shahad Saif Khandker, et al. Nutritional Composition and Bioactive Compounds in Tomatoes and Their Impact on Human Health and Disease: A Review[J]. Foods, 2021, 10(1): 45.
[2] Tan B, You W, Huang C, et al. An intelligent near-infrared diffuse Reflectance Spectroscopy scheme for the non-destructive testing of the sugar content in cherry tomato fruit[J]. Electronics, 2022, 11(21): 3504.
[3] Minas I S, Blanco-Cipollone F, Sterle D. Accurate non-destructive prediction of peach fruit internal quality and physiological maturity with a single scan using near infrared spectroscopy[J]. Food Chemistry, 2021, 335: 127626.
[4] Pourdarbani R, Sabzi S, Kalantari D, et al. Non-destructive visible and short-wave near-infrared spectroscopic data estimation of various physicochemical properties of Fuji apple (Malus pumila) fruits at different maturation stages[J]. Chemometrics and Intelligent Laboratory Systems, 2020, 206: 104147.
[5] Guosheng Zhang, He Hao, Yichen Wang, et al. Optimized adaptive Savitzky-Golay filtering algorithm based on deep learning network for absorption spectroscopy[J]. Spectrochimica Acta Part A: Molecular and Biomolecular Spectroscopy, 2021, 263: 120187.
[6] Chima Robert, Sara J. Fraser-Miller, William T. Jessep, et al. Rapid discrimination of intact beef, venison and lamb meat using Raman spectroscopy[J]. Food Chemistry, 2021, 343: 128441.
[7] Subrato Bharati, Tanvir Zaman Khan, Prajoy Podder, et al. A comparative analysis of image denoising problem: noise models, denoising filters and applications[J]. Cognitive Internet of Medical Things for Smart Healthcare: Services and Applications, 2021: 49-66.
[8] Kok Pin Chan, Mahmud Iwan Solihin, Chun Kit Ang, et al. Experimentation on spectra data regression using dense multilayer neural networks with common pre-processing[M]//Enabling Industry 4.0 through Advances in Mechatronics: Selected Articles from iM3F 2021, Malaysia. Springer, 2022: 97-112.
[9] Xu Chen, Lei Liu, Xin Tan. Robust pedestrian detection based on multi-spectral image fusion and convolutional neural networks[J]. Electronics, 2021, 11(1): 1.
[10] Yonghong Shi, Fengzhong Wang, Hong Xie, et al. Model for prediction of pesticide residues in soybean oil using partial least squares regression with molecular descriptors[J]. Agriculture Communications, 2024, 2(3): 100053.
[11] Janani Venkatraman Jagatha, Christoph Schneider, Tobias Sauter. Parsimonious Random-Forest-Based Land-Use Regression Model Using Particulate Matter Sensors in Berlin, Germany[J]. Sensors, 2024, 24(13): 4193.
[12] 李阳冬,张傑,徐子龙.基于CART回归树的网络安全等级保护判定方法[J].网络安全和信息化,2025,(10):140-142.
作者:张龙1,朱凌飞1,滕广2,朱婷婷2
(1. 菲尼克斯(南京)智能制造技术工程有限公司,江苏 南京 211100;
2. 南京林业大学机械电子工程学院,江苏 南京 210037)
来源:荣格-《 国际食品加工及包装商情》
原创声明:
本站所有原创内容未经允许,禁止任何网站、微信公众号等平台等机构转载、摘抄,否则荣格工业传媒保留追责权利。任何此前未经允许,已经转载本站原创文章的平台,请立即删除相关文章。


