 供需大厅
供需大厅
 登录/注册
登录/注册 供应商登录
供应商登录










荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。
欢迎来到荣格工业资源网!

供需大厅

登录/注册
公众号

更多资讯,关注微信公众号
小秘书

更多资讯,关注荣格小秘书
邮箱
您可以联系我们 info@ringiertrade.com

电话
您可以拨打热线
+86-21 6289-5533 x 269
建议或意见
+86-20 2885 5256
顶部

荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。



让人形机器人能够像人一样完成装箱、搬运、推车等移动操作任务,一直是人们对具身智能的期待。近日,来自香港大学、智元AGIBOT、复旦大学和上海创智学院的联合研究团队提出了 WholeBodyVLA,一种面向真实世界的人形机器人全身 Vision–Language–Action 框架。该工作基于智元灵犀X2研究发布,将 VLA 扩展至双足人形机器人的全身控制,验证了其在全身 loco-manipulation 任务中的可行性。


与原地操作相比,loco-manipulation 的难点不在于单一技能,而在于行走与操作必须在同一任务中长期、稳定地协同发生。围绕这一挑战,WholeBodyVLA 总结出限制 loco-manipulation 发展的两个核心问题:真机数据稀缺以及运动执行中的不稳定性,并引入两项关键方案:
从人类视频中学习:通过从第一视角人类视频中学习移动与操作的潜在动作表示,模型能够不依赖大规模机器人遥操数据,直接获取对 loco-manipulation 行为的统一语义理解,从而显著缓解人形机器人遥操作数据稀缺、采集成本高的问题。
面向移动操作的RL控制器:将通用连续运动控制目标简化为一组离散运动指令,仅保留 loco-manipulation 必要的强化学习训练目标,从而显著提升了控制器在运动执行时的稳定性。

01/
移动操作难在哪儿?
决策层-数据困境:相比原地操作,人形机器人在移动操作任务中的数据采集要“贵”得多。往往需要不止一个数采员同时遥操机器人上半身进行操作、下半身完成行走,这通常只能通过混合方案实现(例如 VR 控制上半身、遥控器控制下半身),这种方式操作流程长、效率低;或者使用全身动捕系统,但价格高昂。再加上人形机器人本身的硬件成本居高不下,使得真机数据难以scale-up,从而让依赖大量真机数据学习操作任务先验知识的 VLA 范式,在人形机器人移动操作场景中变得尤为困难。
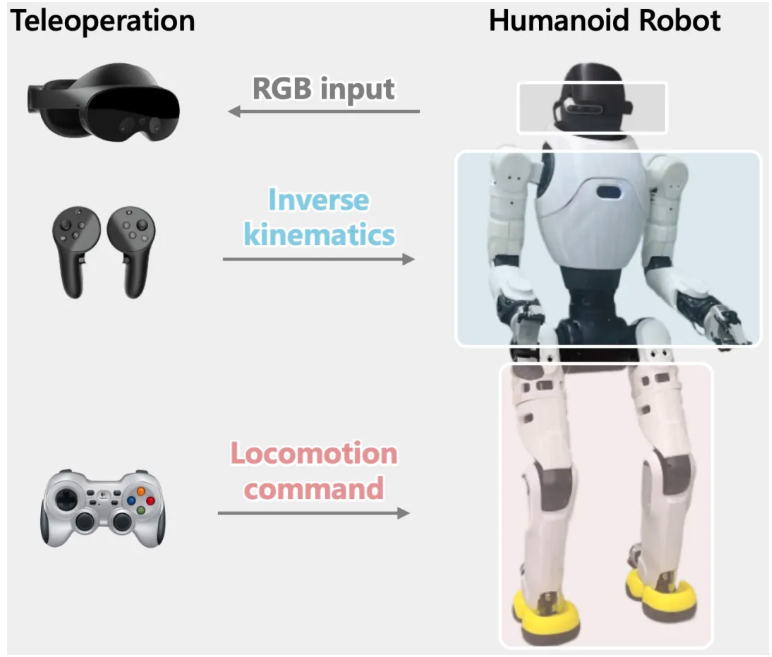
执行层-控制难题:相比纯粹的locomotion,loco-manipulation对运动精准性和稳定性的要求高的多,任何偏离都可能导致目标操作物体脱离相机视野和工作空间。即使 VLA 输出了正确的运动指令,下半身控制器仍然有概率执行失败,例如出现走歪、踉跄等现象。

02/
WholeBodyVLA的解决思路
为了解决这些挑战,研究团队提出了WholeBodyVLA(如下图所示),并引入了两个关键创新:

01
从人类视频中学习
为了缓解数据稀缺,WholeBodyVLA 从低成本的人类第一视角视频中学习 manipulation-aware locomotion 知识。由于这类视频不包含显式动作标注,研究团队首先训练潜在动作模型,为视频自动标注运动与操作潜在动作表示。其中,运动相关的潜在动作从人类第一视角视频中学习,操作相关的潜在动作则基于 AgiBot World 数据集进行建模。

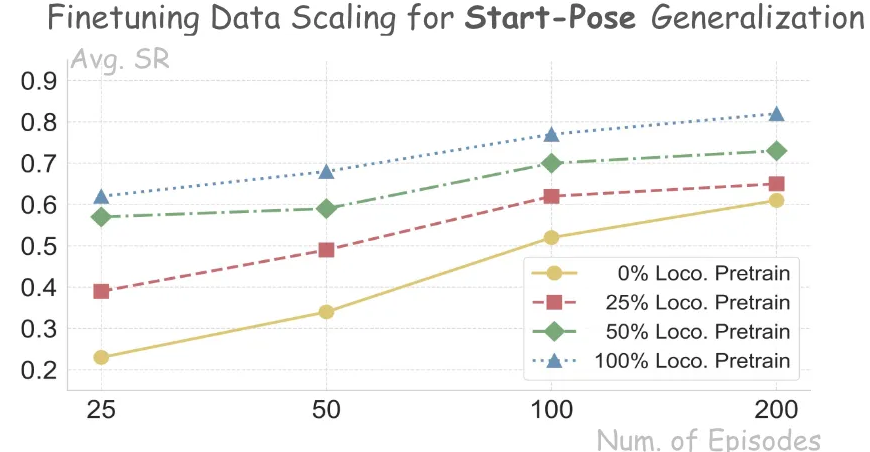
在预训练阶段,WholeBodyVLA 同时预测运动与操作两类潜在动作表示,执行统一潜在动作学习,在共享的潜在空间中对齐移动与操作的动作语义。由于这些潜在动作表示在人类视频与机器人视频之间是共享的,模型能够将从人类视频中学到的移动与操作知识有效迁移到机器人策略上。实验结果表明,随着统一潜在动作学习阶段所使用数据量的增加,模型性能持续提升,显著降低了对高成本遥操作数据的依赖。
02
面向移动操作的RL控制器
对于 loco-manipulation 而言,控制层的执行稳定性与 VLA 的高层决策同样关键。不稳定的下半身运控往往会使任务在进入操作阶段之前就宣告失败,使得 VLA 的上半身操作能力无用武之地。
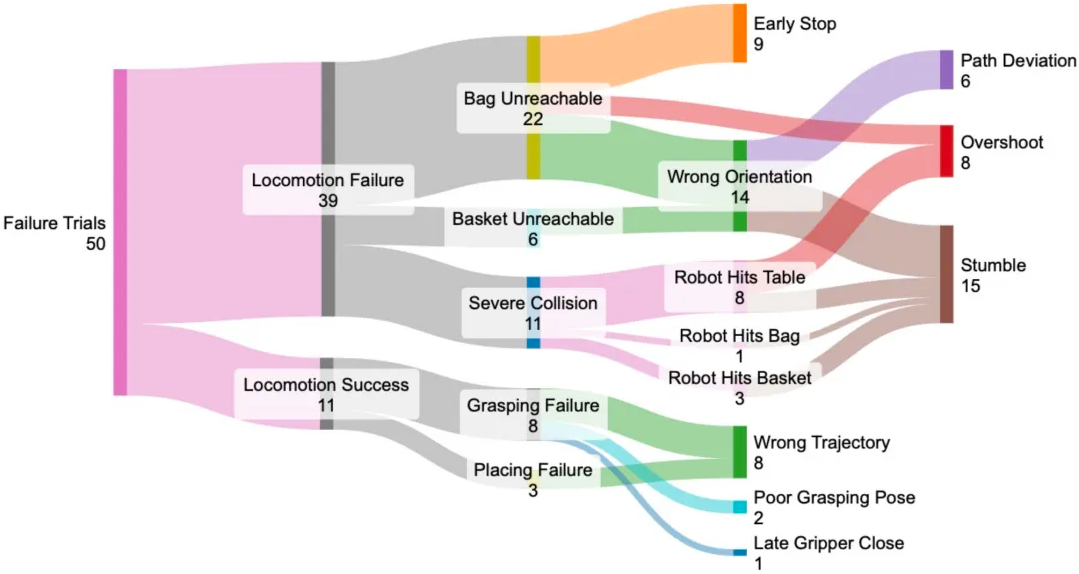
为此,WholeBodyVLA 设计了一种面向 loco-manipulation 的 LMO RL控制器,对下半身强化学习的控制接口与训练目标进行了简化。LMO 不再采用通用的连续速度跟踪,而是仅保留与移动操作相关的离散运动指令,如前进、侧移、转向和下蹲,显著降低了训练和控制的复杂度,增强了运控的稳定性,为操作阶段提供可靠的位姿基础。
03/
实验结果
研究团队在 智元灵犀X2 人形机器人上进行了大量真机实验验证,发现 WholeBodyVLA 具有以下能力(动图有额外加速,原视频见项目主页)。
01
大范围、长程移动操作任务

02
距离泛化性
得益于统一潜在动作学习阶段获取的manipulation-aware locomotion知识,WholeBodyVLA 能从不同的位置出发、并停止在目标物体处完成操作任务。

03
操作泛化性
得益于统一潜在动作学习阶段获取的manipulation知识,WholeBodyVLA 也对不同的场景、物体、位置表现出一定的操作泛化性。

04
地形泛化性
得益于 LMO 改进的运控稳定性,WholeBodyVLA 能够在干扰地形上仍然保持基本准确的移动方向和平衡。

总的来说,WholeBodyVLA 展示了 VLA 扩展到双足人形机器人自主全身控制的可行路径。通过从人类视频中学习,并结合针对移动操作的RL控制器,WholeBodyVLA 使机器人能够在真实世界中稳定完成行走与操作交织的长时序任务,为推动人形机器人走向制造、服务、物流等复杂场景提供重要基础。作为本项研究的共同推动者之一,智元AGIBOT将持续致力于核心前沿技术的创新与探索,推动人形机器人智能从实验室走向广泛的应用场景,为具身智能发展贡献坚实的技术与产业力量。


