 供需大厅
供需大厅
 登录/注册
登录/注册 供应商登录
供应商登录










荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。
欢迎来到荣格工业资源网!

供需大厅

登录/注册
公众号

更多资讯,关注微信公众号
小秘书

更多资讯,关注荣格小秘书
邮箱
您可以联系我们 info@ringiertrade.com

电话
您可以拨打热线
+86-21 6289-5533 x 269
建议或意见
+86-20 2885 5256
顶部

荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。



2025 年接近尾声,AI 在生物制药领域的渗透正从单纯的结构预测迈向更深层的“生物编程”。
10 月 28 日,英伟达(NVIDIA)发布了首个 RNA 基础模型 CodonFM ;同日也宣布与礼来(Eli Lilly)展开算力基础设施合作。制药行业正见证一种从“被动解读”遗传信息向“主动设计”可编程药物的范式转变……
Part 1
核心突破:
破解同义密码子的“沉默”语法
长期以来,生物学界的蛋白质语言模型主要关注氨基酸序列,往往忽略了同义密码子(Synonymous Codons)之间的细微差别——即不同的核苷酸组合虽编码相同的氨基酸,却会导致截然不同的蛋白质产量和 mRNA 稳定性。
据英伟达最新发布的研究显示,其新推出的 CodonFM(Codon Foundation Model) 正是为填补这一空白而来。
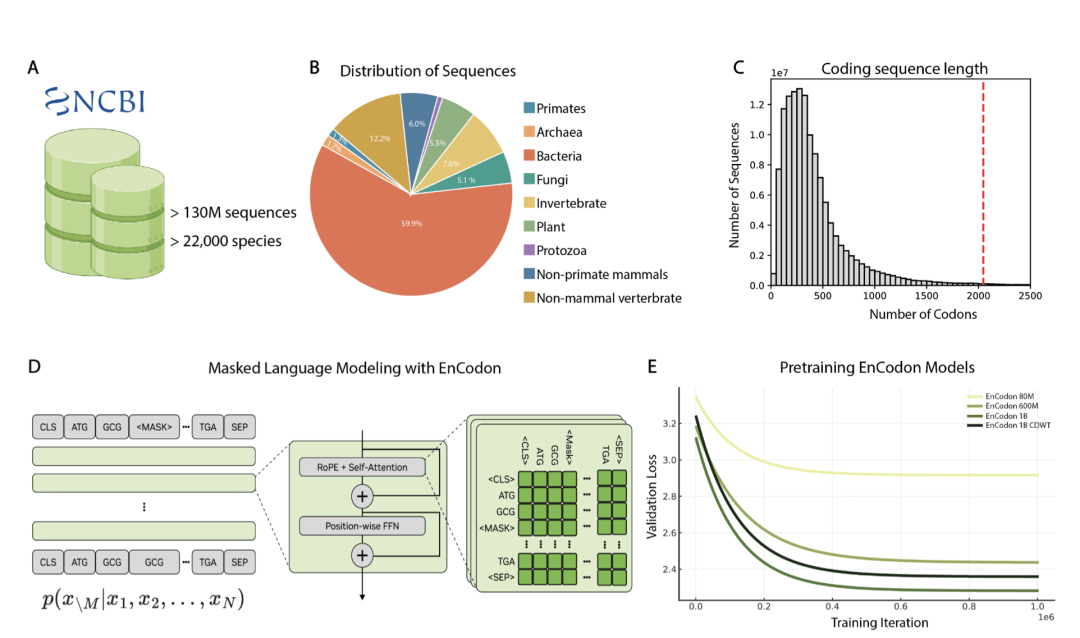
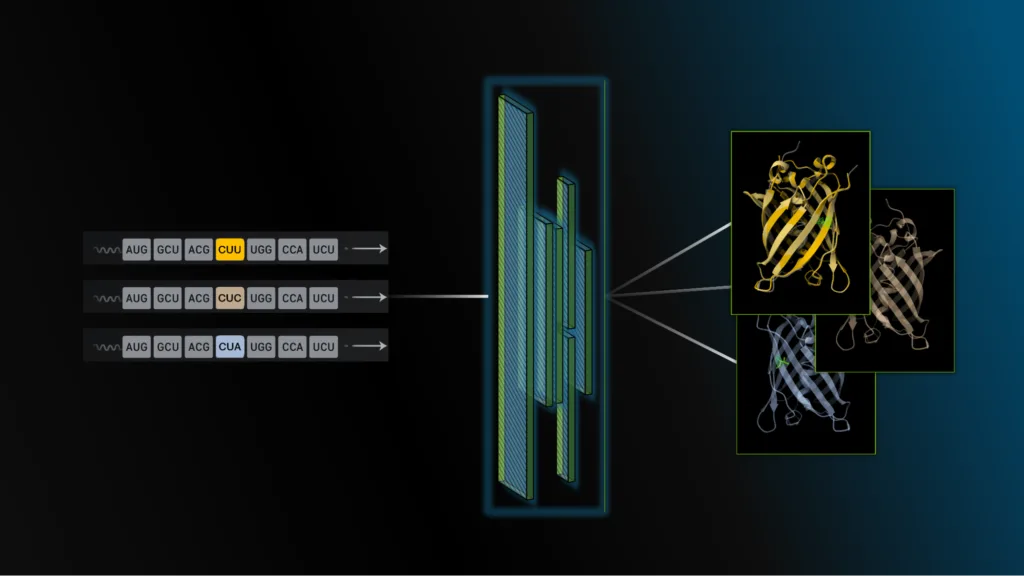
该模型基于 BERT 式双向编码器架构,在来自 2.2 万个物种的 1.31 亿个蛋白质编码序列上进行了训练。
与以往模型不同,CodonFM 将每三个核苷酸组成的密码子(codon)视为“单词”(token),学习其在生物进化中的上下文语法。其核心突破在于——
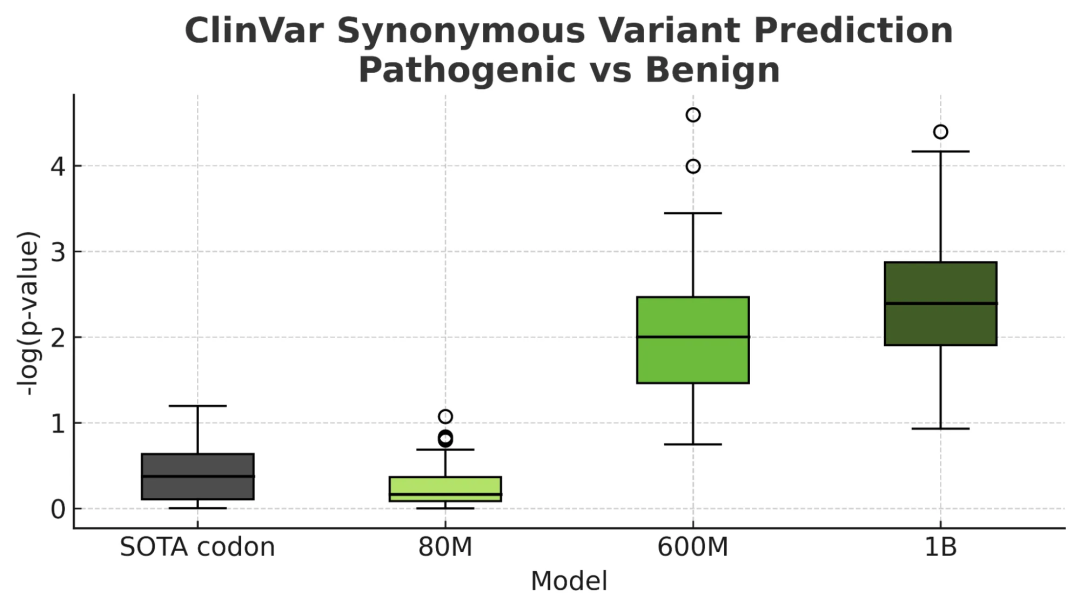
精准预测“沉默”突变风险:传统观点认为不改变氨基酸的同义突变是“沉默”的,但 CodonFM 证明这些突变可能通过改变翻译效率或 mRNA 结构引发疾病。模型在 ClinVar 数据集上的测试显示,其区分致病性与良性同义突变的能力超越了现有的 RNA 基准模型。
mRNA 疗法设计的“导航仪”:对于近年来火热的 mRNA 疫苗和疗法,CodonFM 能够进行零样本预测(Zero-shot prediction),优化序列以提升蛋白质表达丰度和翻译效率。这标志着 mRNA 药物设计正从试错法走向基于规则的“可编程设计”。
在技术细节方面,由英伟达、Arc Institute、加州大学伯克利分校、加州大学旧金山分校、斯坦福大学的研究人员共同完成的 CodonFM 的学术论文提供了模型设计和性能评估的详细信息。

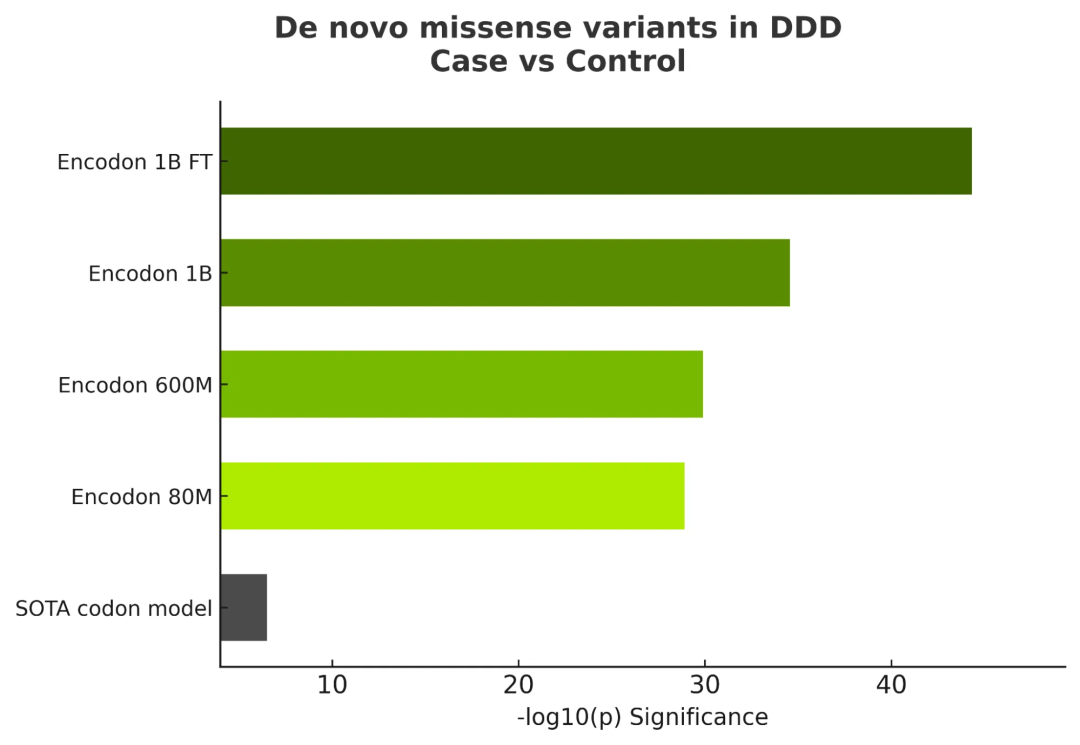
《国际医药商情》观察到,论文展示了不同规模模型在多个任务上的性能对比。在发育障碍和自闭症谱系障碍队列的从头错义突变数据中,EnCodon 模型显示出比其他无监督蛋白质和 RNA 序列模型更强的病例对照变异分离能力。零样本设置下,模型使用参考和突变密码子之间的对数似然差异进行评分,无需任何任务特定训练。
论文还描述了模型嵌入空间的结构。通过对 PCA 降维后的嵌入进行 UMAP 投影,可以看到较大的 EnCodon 模型在所有系统发育分组中实现了更低的掩码语言建模损失,显示出改进的预测准确性和对密码子关系的上下文理解。较大的模型在分类学划分中也显示出更高的 K 近邻纯度,说明它们的嵌入在生物分组方面组织得更加连贯。
主成分与氨基酸疏水性的相关性分析显示,最小的模型在前 10 个主成分中与疏水性等基本性质的相关性更高。这表明高容量模型在生化特征之外还平衡了与密码子使用相关的额外上下文信号。
论文的讨论部分指出了一些局限性。EnCodon 的结果基于计算推断,需要实验验证来确认其生物学相关性。具有实验验证功能效应的同义变异数量仍然很少,这限制了验证数据集,需要谨慎解释统计显著性。模型目前在不明确整合细胞类型特异性 tRNA 丰度、RNA 修饰或二级结构动力学的情况下建模序列特征,而这些因素在体内调节翻译。
研究团队表示,通过扰动分析、核糖体图谱分析和合成 mRNA 设计实验整合这些上下文依赖数据并验证预测,对于将 EnCodon 的见解转化为机制和治疗应用至关重要。
Part 2
基础设施:
算力与生态的双重加持
单纯的模型算法并不足以撼动万亿级的制药产业,算力和生态的协同至关重要。在 CodonFM 发布的同时,《国际医药商情》留意到,两项关键的行业动态为其落地提供了坚实支撑。
首先是算力工厂(AI Factory)的建立。
就在 CodonFM 亮相的同期,制药巨头礼来(Eli Lilly)宣布与英伟达达成历史性合作,利用超 1000 个 GPU 构建制药行业“最强”超级计算机。

“AI 工厂”不仅服务于新药发现,更将贯穿从规划到制造的全生命周期。这表明,头部药企已不再满足于外包 AI 服务,而是正在构建能运行如 CodonFM 这类大模型的自有基础设施。

其次是开源生态的构建。
为了加速科研转化,英伟达与 Chan Zuckerberg Initiative (CZI) 达成深度合作,将 CodonFM 及其他 Clara 开放模型集成至 CZI 的虚拟细胞平台(Virtual Cells Platform)。

这一举措极大降低了科研人员使用高门槛 AI 模型的障碍,使得从斯坦福 RNA 医学计划到各类生物科技初创公司,都能直接调用该模型进行变异效应预测和 mRNA 设计。
Part 3
行业趋势:
从“假设”走向“临床验证”
回顾 2025 年全年,AI 制药行业正处于去伪存真的关键期。虽然 AI 在药物发现中的应用已有时日,但过去的 2024-2025 这两年是真正的“临床验证年”。
Insilico Medicine 等企业的 AI 设计药物进入临床,赛诺菲(Sanofi)、阿斯利康(AstraZeneca)等巨头在肿瘤和免疫领域的重金布局之下,行业焦点已从“AI 能不能发现分子”转移到了“AI 设计的分子的临床成功率是否更高”。
英伟达 CodonFM 这类技术的出现,为这一进程提供了新的维度的工具。它不再局限于寻找靶点或小分子筛选,如以往的 MolMIM 和 DiffDock 流程等,而是深入到了基因表达调控的底层逻辑。这对于难以成药的靶点,或是需要精细调控表达量的基因疗法而言,无疑是一剂强心针。
正如大语言模型学会了人类语言的语法从而能撰写文章,CodonFM 正在通过学习遗传密码的“语法”来理解生物学行为。
未来,结合药企的庞大实验数据与更强的算力底座,我们或许很快就能看到由 AI 完全“编程”设计的 mRNA 疗法进入临床,不仅精准治疗疾病,且副作用更低、研发周期更短。
在此刻,生物学正在真正成为一门数据科学。
参考资料:
Introducing the CodonFM Open Model for RNA Design and Analysis - NVIDIA
Lilly Deploys World’s Largest, Most Powerful AI Factory for Drug Discovery Using NVIDIA Blackwell-Based DGX SuperPOD - NVIDIA
CZI and NVIDIA Accelerate Virtual Cell Model Development for Scientific Discovery - The Chan Zuckerberg Initiative
来源:国际医药商情
作者:John Xie


