 供需大厅
供需大厅
 登录/注册
登录/注册 供应商登录
供应商登录










荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。
欢迎来到荣格工业资源网!

供需大厅

登录/注册
公众号

更多资讯,关注微信公众号
小秘书

更多资讯,关注荣格小秘书
邮箱
您可以联系我们 info@ringiertrade.com

电话
您可以拨打热线
+86-21 6289-5533 x 269
建议或意见
+86-20 2885 5256
顶部

荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。



【背景介绍】
排序作为一种核心操作,广泛应用于数据库管理、人工智能(AI)推理、网页搜索、科学计算等多个关键领域,成为现代计算中不可或缺的基础性任务。然而,传统的硬件排序系统大多依赖冯·诺依曼架构,这种架构在大规模数据处理时容易遭遇带宽瓶颈,特别是在数据量急剧增加的情况下,存储与计算单元之间频繁的数据传输会极大限制系统的性能。
尽管现有的硬件排序方法,如 CPU、GPU 和 ASIC 等,通过提高并行性和计算能力有所改进,但它们依然依赖于大量的比较操作和数据交换。这不仅增加了计算的复杂性,还使得系统在面对庞大数据集时性能逐渐饱和。因此,如何突破传统计算架构的限制,提升排序效率,成为了计算机体系结构领域的重要方向。
为了解决这一问题,研究者们提出了基于忆阻器(Memristor)技术的创新方案——“存内排序”技术(Sort-in-Memory, SIM)。这一技术通过将数据排序直接嵌入存储器中,从而减少了传统计算模型中不可避免的数据传输和比较操作,显著提高了排序效率。忆阻器具有高密度、非易失性和低功耗的特点,使得在存储器中完成排序成为可能。
北京大学杨玉超教授和陶耀宇研究员提出了一种创新的无比较排序系统——Memory-Sort-In-Memory(MSIM)。该系统采用忆阻器阵列作为核心组件,通过直接在内存中执行排序操作,消除了传统排序系统中依赖比较单元的瓶颈。
为了进一步优化排序过程,MSIM 系统引入了 Tree Node Skipping(TNS)策略,该策略通过智能跳过冗余的树节点遍历,显著减少了不必要的计算,提升了排序效率。与传统的基于 CMOS 技术的排序系统相比,MSIM 在排序速度、能效和面积效率等方面均取得了显著进展,尤其在处理大规模数据时展现出更为出色的性能。
通过一系列验证,MSIM 系统在多个实际应用场景中,如最短路径搜索和神经网络推理等,表现出卓越的性能和显著的节能优势。特别是在最短路径问题的求解中,MSIM 系统通过减少排序操作的周期,极大地提升了计算效率;在神经网络推理中,MSIM 不仅加速了数据处理,还优化了能效,证明了其在计算密集型任务中的巨大应用潜力。
MSIM 系统为现代计算任务提供了一种具有高效性、低能耗和高扩展性的解决方案。该文章以“A fast and reconfigurable sort-in-memory system based on memristors”为题发表在国际顶级期刊Nature Electronics上。

【图文精读】
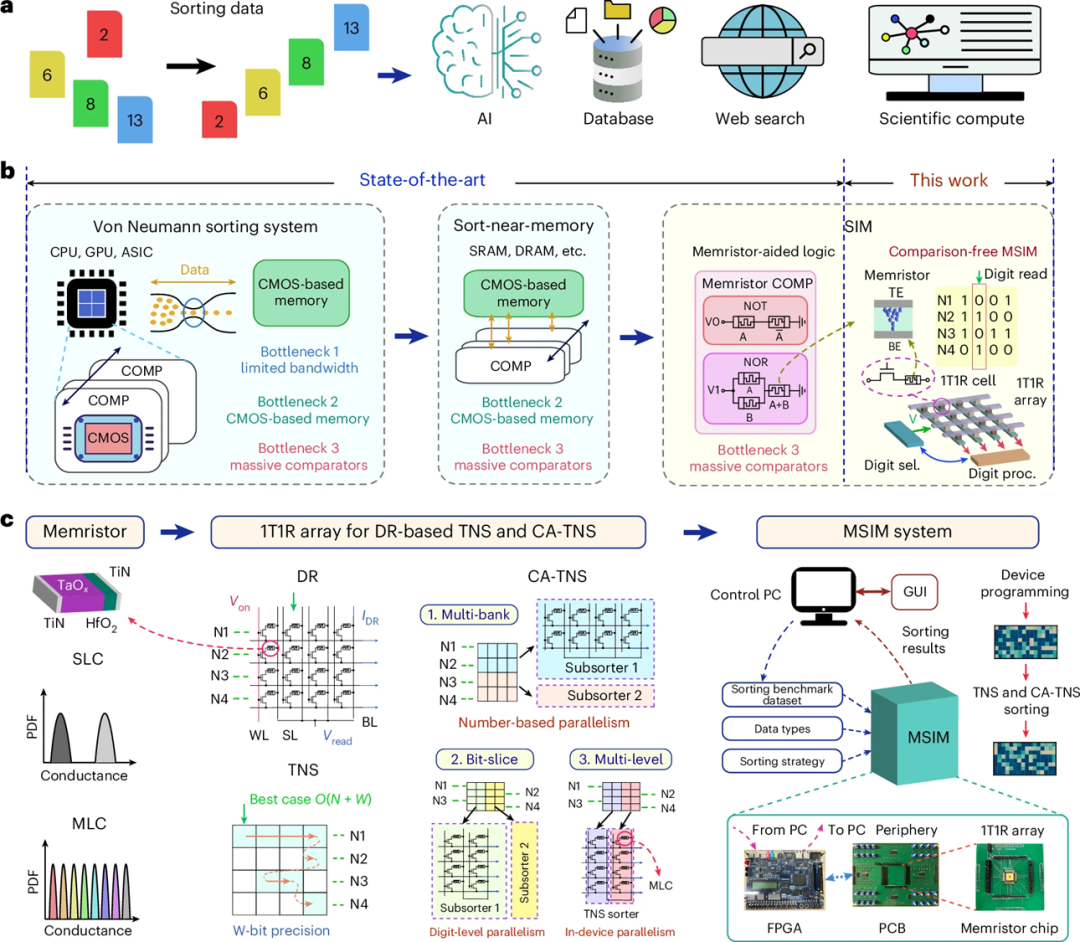
图1-排序系统概述:图 1 展示了不同类型排序系统的全景比较,尤其强调了传统的基于 CPU、GPU 和 ASIC 的排序架构。这些系统依赖于冯·诺依曼架构,其中计算单元和内存单元之间的频繁数据传输往往会引发带宽瓶颈,导致在处理大规模数据时性能显著下降。
为了解决这一问题,本文提出了基于忆阻器的 Sort-in-Memory(SIM)系统,这一创新架构通过将排序任务直接集成至存储器中,减少了数据传输的频率,从而显著提升了系统性能。
特别地,本文所提出的 Memory-Sort-In-Memory(MSIM)系统通过消除传统排序方法中的比较操作,避免了冯·诺依曼架构中的固有瓶颈,优化了排序效率,提升了能效和面积效率。这种无比较的排序方法不仅突破了传统技术的限制,还为大数据处理提供了一种全新的思路。
要点总结:
传统排序系统在大数据处理时因内存带宽和数据传输的瓶颈而性能受限。
MSIM 系统通过存内计算和无比较操作,消除了冯·诺依曼架构的瓶颈,提升了排序效率,特别适用于大规模数据集。
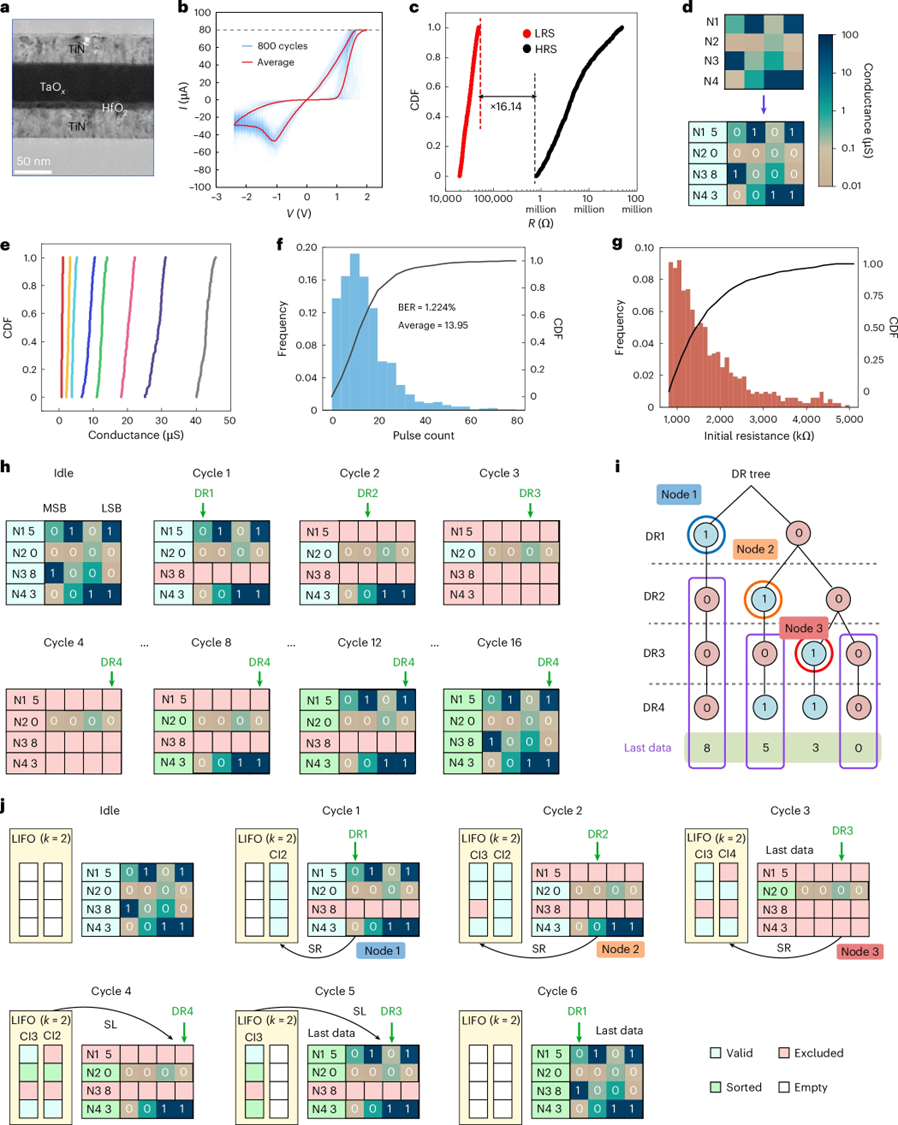
图2-忆阻器编程与 TNS:图 2 详细展示了忆阻器阵列在排序任务中的应用,包含了忆阻器的 I-V 性能特性以及其在排序过程中的表现。通过比较传统的位遍历排序(BTS)与提出的树节点搜索(TNS)方法,图中揭示了 TNS 在排序效率上的显著优势。
TNS 利用树节点的逐步搜索和遍历方式,从最重要位(MSB)到最不重要位(LSB)逐步查找最小值和最大值,而这一过程避免了传统排序中常见的频繁写操作和冗余的读操作,显著降低了排序延迟。通过忆阻器编程的高密度存储特性,TNS 在节省内存空间的同时也提升了存储效率,使得大数据排序变得更加高效。实验数据表明,TNS 方法在减少排序所需周期的同时,极大提升了能效和计算速度。
要点总结:
传统排序方法如 BTS 存在操作复杂和周期冗长的问题,而 TNS 通过树节点遍历优化,显著减少了冗余操作,提高了排序效率。
TNS 利用忆阻器的编程特性,通过减少读操作并提升存储密度,实现了排序效率和能效的显著提升。

图3-CA-TNS 策略:图 3 介绍了交叉阵列树节点搜索(CA-TNS)策略,针对大规模数据集排序时的扩展性问题,提出了数字并行(MB)、位并行(BS)和器件内并行(ML)三种策略。每种策略通过不同的并行化方式对排序任务进行优化,从而提升处理效率。
数字并行策略通过将数据集划分为多个部分,使每个部分独立进行排序,从而提高了并行处理的能力并减小了排序延迟。位并行策略将数据按位进行切分,在多个子阵列中并行处理,从而加速了排序过程,特别适用于需要高精度排序的场景。器件内并行策略则通过在设备内部进行更深层次的并行处理,进一步提升了排序速度和存储效率。CA-TNS 策略的引入不仅有效应对了大规模数据排序的挑战,还通过高度的并行化显著提高了计算和存储的效率。
要点总结:
CA-TNS 策略(MB、BS、ML)通过多层次并行化显著提升了大数据集排序的效率,解决了排序扩展性问题。
每种策略通过不同方式优化存储与处理过程,提升了数据处理速度,并有效减少了排序所需的时间和能耗。
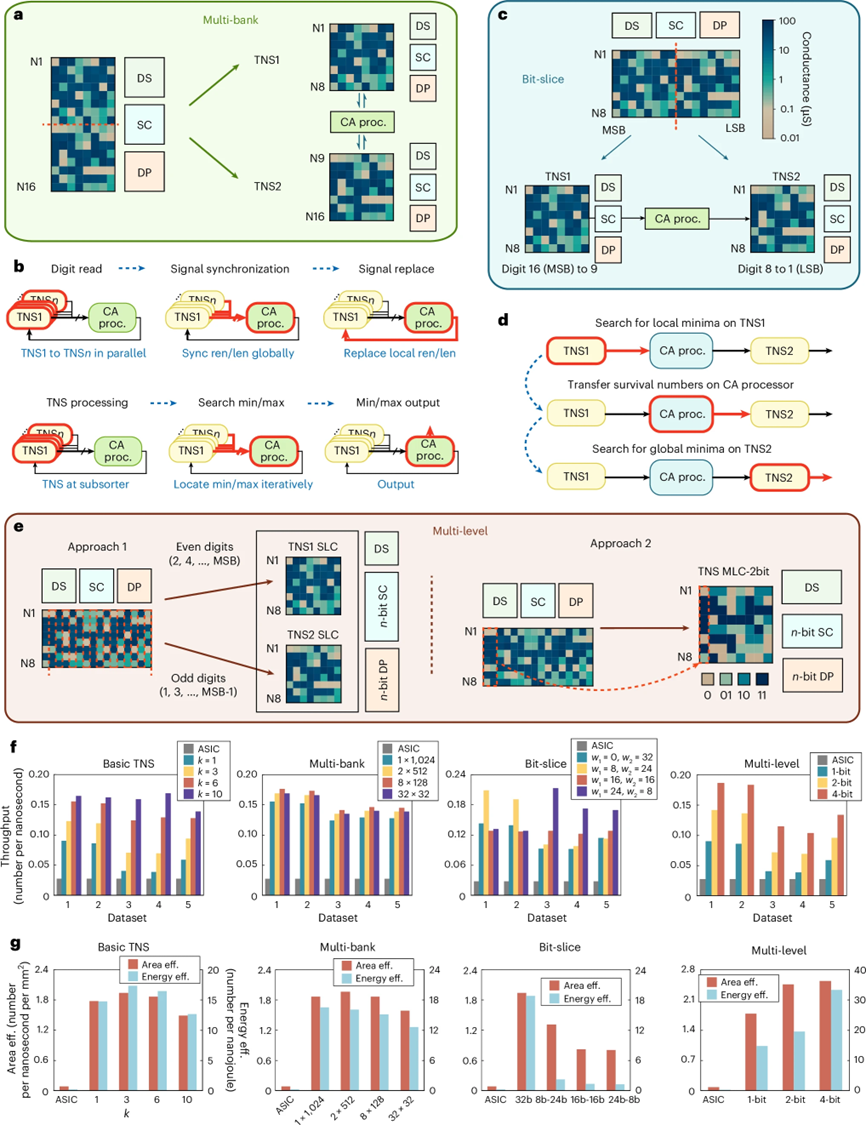
图4-CA-TNS 策略性能评估:图 4 对 CA-TNS 策略在五个排序基准数据集上的性能进行了综合评估,分别从排序速度、能效和面积效率等多个维度对比了不同策略的表现。数字并行(MB)策略通过将数据集分配至多个部分,提升了大数据集的处理速度,同时降低了排序延迟;位级并行(BS)策略通过位级并行处理加速了排序过程,尤其在处理精度要求较高的数据时表现尤为突出;器件内并行(ML)策略则通过更高的存储密度和内部并行计算,进一步优化了排序的整体性能。
实验结果表明,相较于传统的 ASIC 排序方法,CA-TNS 策略在各项性能指标上均表现优异,尤其在大规模数据排序中展示了更强的优势,能够在较短的时间内完成复杂的排序任务,同时显著减少能耗和占用空间。
要点总结:
CA-TNS 策略(MB、BS、ML)显著提高了排序速度,优化了能效和面积效率,在所有评估维度上超越了传统的 ASIC 排序方法。
各策略针对不同应用场景优化了并行处理和存储,提升了数据处理的速度和能效,特别适用于大规模数据集的高效排序。
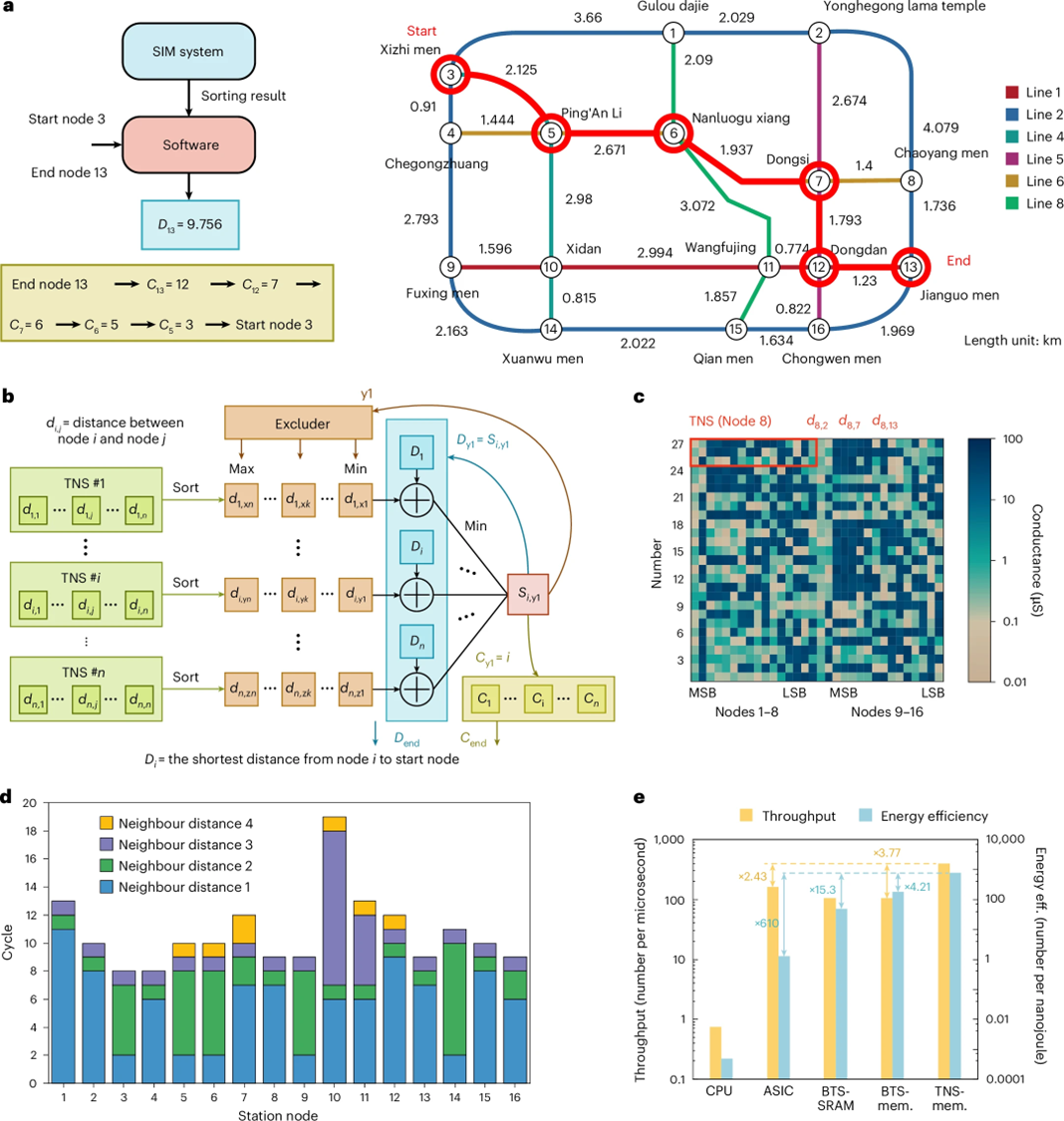
图5-TNS 在最短路径搜索中的实验:图 5 通过实验展示了 TNS 在 Dijkstra 算法中的应用,具体使用了北京 16 个地铁站的图模型进行最短路径搜索。图中展示了如何使用 TNS 对各个站点之间的距离进行排序,以便在计算最短路径时加速数据处理。
实验结果表明,TNS 在排序过程中大大减少了操作周期,相比于传统的排序技术,不仅提高了计算速度,而且显著优化了能效。在最短路径搜索等图计算任务中,TNS 展现了其在实时性和计算效率方面的巨大优势,特别是在处理大规模图数据时,能够有效减少计算时间和能量消耗。
要点总结:
TNS 在最短路径搜索中通过减少排序操作显著提升了计算效率,优化了路径计算的实时性。
在吞吐量和能效方面,TNS 超越了其他排序技术,尤其适合实时图计算任务和大规模数据处理。
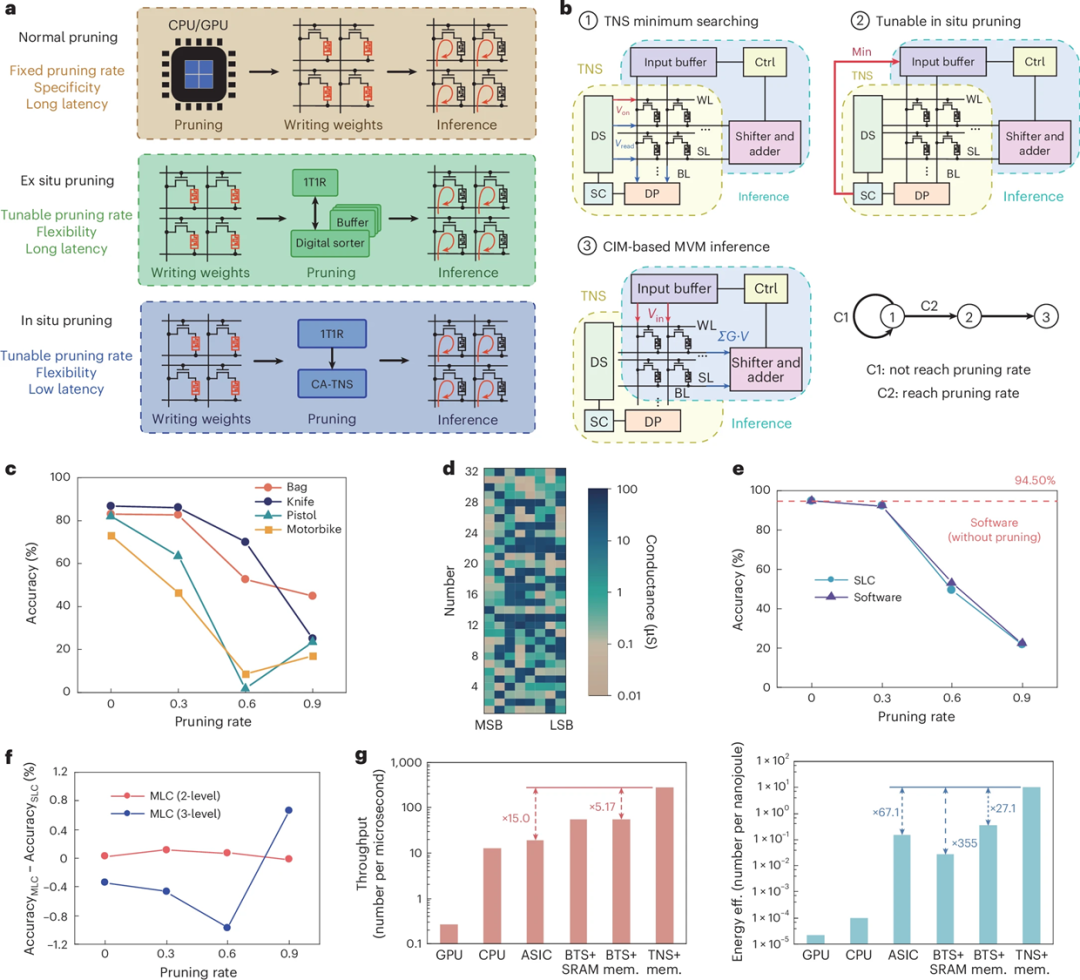
图6-PointNet++中的原位剪枝:图 6 探讨了原位剪枝(In-Situ Pruning)在神经网络推理中的应用,特别是对于 PointNet++ 网络。传统的剪枝方法通常在训练阶段进行固定的剪枝,而原位剪枝则允许在推理过程中动态调整剪枝率,从而实现更高效的计算。
图中展示了正常剪枝、外部剪枝和原位剪枝在不同剪枝率下对推理准确度、吞吐量和能效的影响。实验结果表明,原位剪枝能够在较低的计算成本下保持较高的准确性,同时显著提高能效和吞吐量。此外,通过结合多级存储单元(MLC),原位剪枝进一步优化了存储密度和计算速度,在保持较高准确度的同时降低了能量消耗和计算复杂度。
要点总结:
原位剪枝在推理过程中动态调整剪枝率,能够在不显著牺牲准确性的前提下,大幅提升推理效率、吞吐量和能效。
结合多级存储单元(MLC)后,原位剪枝不仅提高了存储密度,还有效降低了推理过程中的能耗和计算负担。
【文献总结】
本文提出了一种创新的基于忆阻器的硬件与软件协同设计的存内排序系统(SIM)。该系统由 TaOx 和 HfO2 智能忆阻器阵列芯片、外围电路和 FPGA组成,旨在消除传统排序方法中的比较单元及其数据传输瓶颈。
为实现无比较排序,本文开发了树节点跳跃(TNS)策略,并针对特殊情况(如重复数字和数据集中的最后一个数字)进行了优化。此外,本文还将基本 TNS 扩展为交叉阵列 TNS(CA-TNS)策略,包括数字并行处理(MB), 位级并行处理(BS),器件并行处理(ML)三种策略,以提升数字级、器件内并行性和存储密度。
实验结果表明,与基于 CPU/GPU 或 ASIC 的传统排序系统相比,MSIM 系统在排序速度、能效和面积效率方面实现了显著提升。该系统支持多种数据量、数据类型和精度,能够灵活适应不同应用需求。通过将 MSIM 应用于 Dijkstra 算法的最短路径搜索和具有动态稀疏性调节的神经网络(PointNet++)推理,验证了该系统在解决实际排序问题中的高效性,并证明了其与传统存内矩阵-向量乘法(MVM)技术的兼容性,为现代计算任务提供了强大的解决方案。
文章信息:Yu, L., Zhang, T., Wang, Z. et al. A fast and reconfigurable sort-in-memory system based on memristors. Nat. Electron. 8, 597–609 (2025).
https://doi.org/10.1038/s41928-025-01405-2
*声明:本文系原作者创作。文章内容系其个人观点,我方转载仅为分享与讨论,不代表我方赞成或认同,如有异议,请联系后台。


