 供需大厅
供需大厅
 登录/注册
登录/注册 供应商登录
供应商登录










荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。
欢迎来到荣格工业资源网!

供需大厅

登录/注册
公众号

更多资讯,关注微信公众号
小秘书

更多资讯,关注荣格小秘书
邮箱
您可以联系我们 info@ringiertrade.com

电话
您可以拨打热线
+86-21 6289-5533 x 269
建议或意见
+86-20 2885 5256
顶部

荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。



来源 / Rambus;荣格电子芯片编译
人工智能正在众多技术市场中催生惊人的增长。这一点在AI训练集的增长中得到了有力体现,其规模正以每年10倍的速度增长,并且预计在这十年内将继续增长。
训练AI系统的两个不同计算使用时代
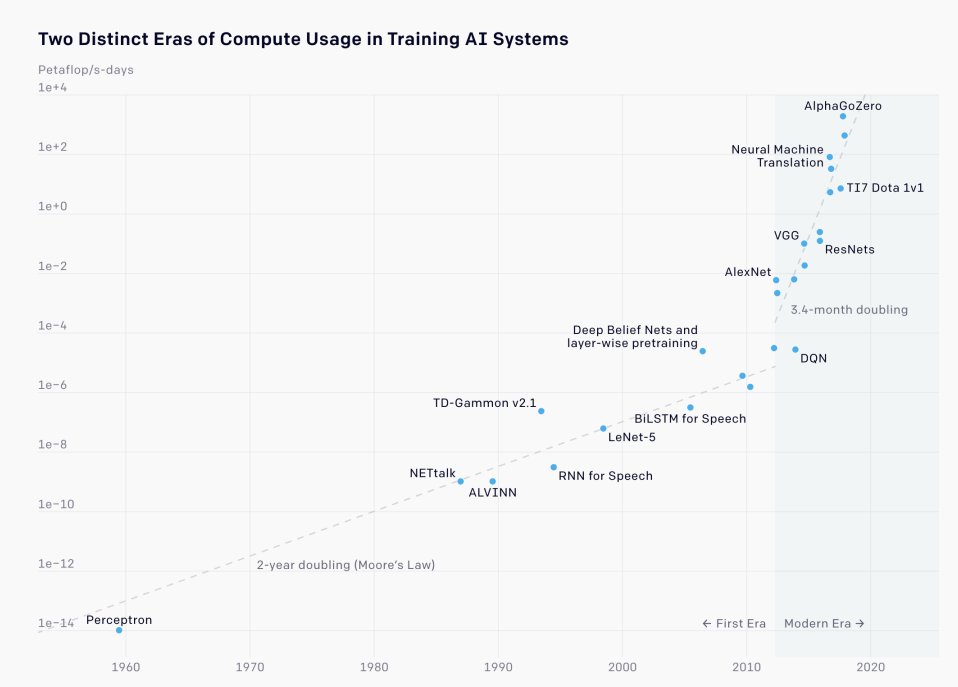
要跟上这种发展速度,仅靠摩尔定律所能实现的改进是远远不够的,何况摩尔定律本身也在放缓。这就需要人工智能计算机硬件和软件的各个方面都持续快速改进。
随着我们进入计算的下一个时代并推动人工智能的持续发展,内存带宽将成为关键关注领域之一。
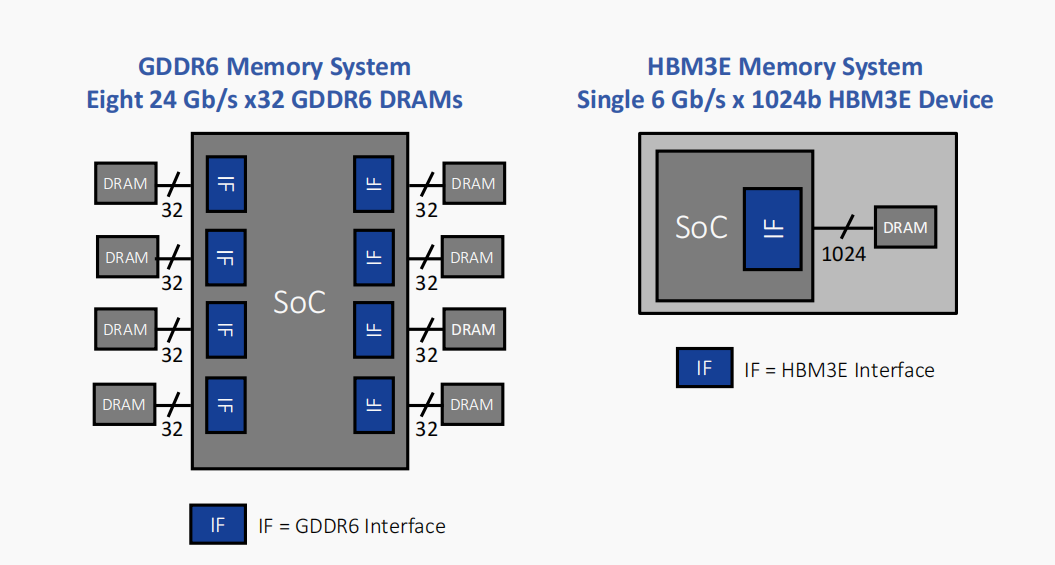
GDDR6和HBM3E具有不同的优势,在设计上需要权衡考量。在为AI/ML应用选择HBM3E和GDDR6时,设计师必须考虑许多权衡因素和关键指标,包括成本、功耗、容量和实现复杂性。
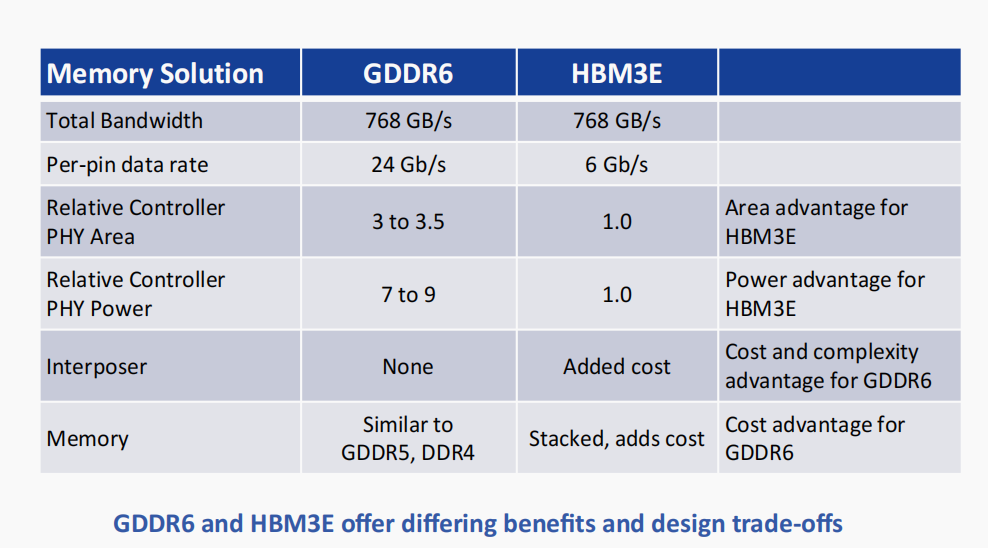
在本白皮书中,我们将探讨HBM3E和GDDR6的优势和设计注意事项。我们还将重点介绍每种内存在整个AI/ML架构中的适用性。最后,我们将讨论可用于实现完整内存子系统的Rambus HBM3E和GDDR6内存控制器解决方案。
Part 1
从HBM2到HBM3E:堆叠技术的进化与性能飞跃
高带宽内存(HBM)是一种高性能的2.5/3D堆叠SDRAM架构。2013年推出的第二代HBM2规定每个堆叠最多8个内存芯片,引脚传输速率为2 Gb/s。HBM2每个封装(DRAM堆叠)实现256 GB/s的内存带宽,HBM2规范支持每个封装高达8 GB的容量。
2018年底,JEDEC发布了HBM2E规范,以支持更高的带宽和容量。随着每引脚传输速率提升至3.6 Gb/s,HBM2E每个堆叠可实现461 GB/s的内存带宽。此外,HBM2E支持12层堆叠,每个堆叠的内存容量高达24 GB。
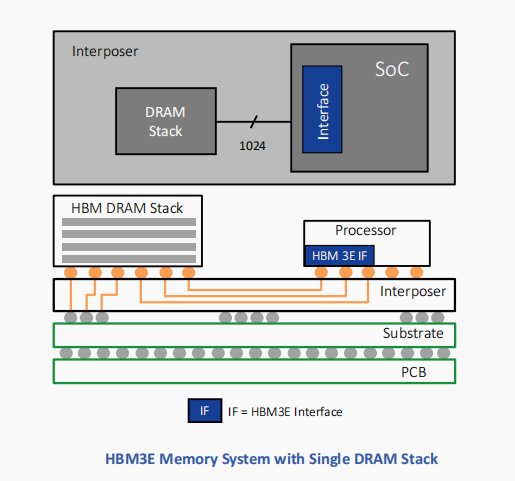
HBM3代标准于2022年推出,能够实现更高的内存带宽。通过6.4 Gb/s运行的接口连接到处理器的四个HBM3堆叠可提供超过3.2 TB/s的带宽。
借助内存的3D堆叠,可在极小的空间内实现高带宽和高容量。此外,通过保持相对较低的数据速率以及内存与处理器的近距离,整体系统功耗得以保持较低水平。
随着对更高内存带宽的需求持续增长,行业已推出工作速率达9.6 Gb/s及以上的HBM3E存储设备。Rambus支持运行速率高达9.6 Gb/s的HBM3E接口,充分展示了这种内存架构的全部功能。
所有版本的HBM都以“相对较低”的数据速率运行,但通过极宽的接口实现了非常高的带宽。例如,运行速率高达6.4 Gb/s的HBM3堆叠通过1024条数据“线”的接口连接到其相关处理器。
加上命令和地址,线的数量增加到约1700条。这远远超过了标准PCB的支持能力。因此,硅中介层被用作连接内存堆叠和处理器的中介。与SoC一样,可在硅中介层中蚀刻精细间隔的数据迹线,以实现HBM接口所需的线数。
HBM的设计权衡在于复杂性和成本的增加。中介层是必须设计、表征和制造的附加元件。与制造传统DDR型内存(包括GDDR)所积累的巨大产量和制造经验相比,3D堆叠内存的出货量相形见绌。最终,HBM3E/3的实现和制造成本高于GDDR6。

图片来源 / 豆包
然而,对于AI训练应用,HBM3E/3的优势使其成为更优选择。其带宽性能卓越,更高的实现和制造成本可以通过节省板空间和功耗来权衡。
在物理空间日益受限的数据中心环境中,HBM3E/3的紧凑架构提供了切实的优势。其较低的功耗意味着更低的热负荷,而在数据中心环境中,冷却通常是首要的运营成本之一。
总之,HBM3E/3为系统设计师提供了极高的带宽能力和最佳的电源效率。尽管由于更大的设计复杂性和制造成本,HBM3E/3系统的实现可能具有挑战性,但板空间和冷却方面的节省可能非常可观。
对于AI训练,HBM3E/3是理想的解决方案。它建立在HBM2和HBM2E的成功基础之上,这些产品已在领先的AI加速器中得到应用。
Part 2
GDDR6设计难点:24 Gb/s信号完整性的极限挑战
图形DDR SDRAM(GDDR SDRAM)最初是为二十多年前的游戏和图形市场设计的。在此期间,GDDR经历了几次重大演变,最新一代GDDR6的数据速率高达24 Gb/s。
GDDR6在带宽、容量、延迟和功耗方面实现了令人印象深刻的组合。Rambus支持运行速率为24 Gb/s的GDDR6接口,充分展示了这种内存架构的全部功能。
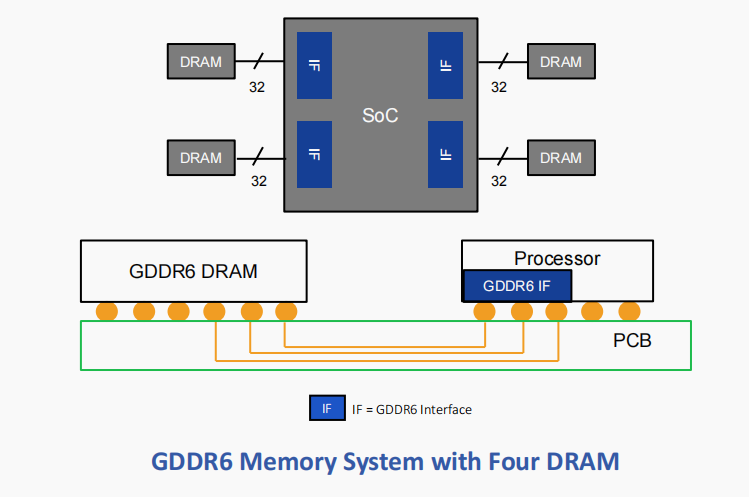
与HBM3E/3不同,GDDR6 DRAM依赖于与生产标准DDR型DRAM相同的高容量制造和组装技术。更具体地说,GDDR6采用传统方法,通过标准PCB将封装和测试后的DRAM与SoC连接在一起。利用现有基础设施和流程为系统设计师提供了熟悉感,从而降低了成本和实现复杂性。
基于经过时间考验的制造工艺,GDDR6内存出色的性价比使其成为AI推理应用的绝佳选择。
与HBM3E/3的宽而慢的内存接口不同,GDDR6接口窄而快。两个16位宽的通道(32条数据线)将GDDR6 PHY连接到相关的SDRAM。在每引脚24 Gb/s的速率下,GDDR6接口可提供96 GB/s的带宽。
GDDR6实现的主要设计挑战源于其最强特性之一:速度。在24 Gb/s的速度下保持信号完整性(SI),尤其是在较低电压下,需要丰富的专业知识。设计师面临更严格的时序和电压裕量,同时损耗源的数量及其影响都迅速增加。接口、封装和板的行为之间的相互依赖关系要求采用这些组件协同设计的方法,以保持系统的信号完整性。
总之,基于可靠的制造工艺,GDDR6内存出色的性能特性使其成为AI推理的理想内存解决方案。其性价比特性使其适合在广泛的边缘网络和物联网端点设备中大规模部署。
总之,GDDR6集带宽、容量、电源效率、可靠性和性价比于一体。有了Rambus这样值得信赖的合作伙伴,SoC设计师可以在应对24 Gb/s运行速度带来的设计挑战的同时,实现所有这些优势。
Part 3
全栈覆盖:AI生态需要HBM3E与GDDR6的互补
鉴于AI/ML的双重性质,内存的选择取决于应用场景:训练或推理。这不是“或”的问题,而是“和”的问题,因为HBM3E和GDDR6这两种高带宽内存都可以发挥至关重要的作用。
对于训练而言,带宽和容量是关键要求。考虑到训练集每年增长10倍,情况尤其如此。训练工作负载现在运行在大规模并行架构上。鉴于训练所创造的价值,存在强大的“上市时间”激励,以尽快完成训练运行。此外,训练应用在数据中心运行,电源和空间日益受限,因此对提供电源效率和更小尺寸的解决方案有很高的要求。
考虑到所有这些要求,HBM3E是AI训练硬件的理想内存解决方案。它提供了出色的带宽和容量能力。该接口具有16个独立通道,每个通道包含64位,总数据宽度为1024位。在标准数据速率6.4 Gb/s下,这提供了819.2 GB/s的总接口带宽。其2.5/3D结构以非常紧凑的形式提供了这些功能,并且由于接口速度低以及内存和处理器之间的接近性,功耗更低。
在推理方面,由于需要实时行动,带宽和延迟至关重要。随着推理部署在广泛的边缘和端点设备上,实现需要比数据中心核心更具成本敏感性。
对于AI推理这一日益具有挑战性的领域,GDDR6是理想的解决方案。它可以通过单个或少量DRAM设备提供出色的带宽:在24 Gb/s数据速率下,每个GDDR6存储设备的内存带宽为96 GB/s。基于成熟的制造工艺,它提供了适合大规模部署的性价比特性。
其结果是,AI/ML并非单一的,训练和推理都需要针对其特定要求的内存解决方案。HBM3E和GDDR6分别满足训练和推理的需求,提供了这些应用所需的一系列强大优势。
如前所述,HBM3E和GDDR6在实现时都面临设计挑战。但有了Rambus这样值得信赖的合作伙伴提供的解决方案,这些内存的优势可以很容易地实现。
Part 4
从设计到落地:Rambus如何简化AI内存集成难题?
Rambus HBM3E/3内存控制器
Rambus HBM3内存控制器针对高带宽和低延迟进行了优化,以紧凑的外形和高效的电源效率为AI训练提供了最大的性能和灵活性。
Rambus HBM3E/3内存控制器使最大HBM2E信令速度翻倍以上,将数据速率提高到市场领先的每数据引脚9.6 Gb/s(远高于6.4 Gb/s的标准速度)。
该接口具有16个独立通道,每个通道包含64位,总数据宽度为1024位。在最大数据速率下,这为每个连接的HBM3E/3存储设备提供了1228.8 GB/s或1.23 TB/s的总接口吞吐量。
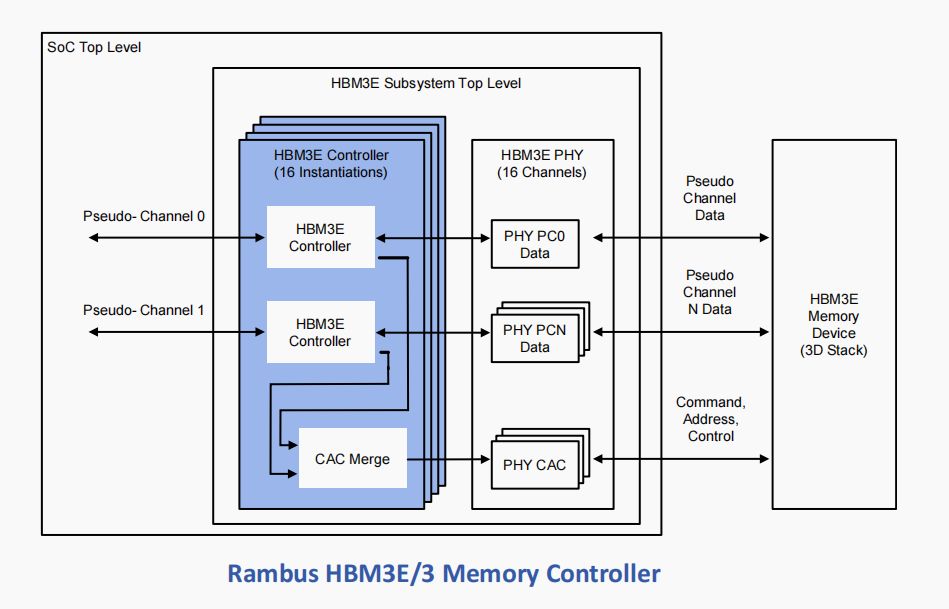
核心通过简单的本地接口接受命令,并将其转换为HBM3E/3设备所需的命令序列。核心还执行所有初始化、刷新和掉电功能。核心在命令队列中排队多个命令。这使得对于短传输到高度随机的地址位置以及长传输到连续的地址空间,都能实现最佳的带宽利用率。
命令队列还用于机会性地执行预激活、预充电和自动预充电,进一步提高整体吞吐量。重新排序功能完全集成到控制器命令队列中,提高了吞吐量并最小化了门数。
其他关键特性包括:
- 支持HBM3E/3存储设备
- 支持所有标准HBM3E/3通道密度(高达32 Gb)
- 支持高达9.6 Gb/s/引脚(HBM3E)或8.4 Gb/s/引脚(HBM3)
- 刷新管理(RFM)支持
- 通过预命令处理最大化内存带宽并最小化延迟
- 集成重新排序功能
- 在最小的路由限制下实现高时钟速率
- 自刷新和掉电低功耗模式
- 支持HBM3E/3 RAS功能
- 内置硬件级性能活动监视器
- 兼容DFI
- 端到端数据奇偶校验
- 支持到用户逻辑的AXI或本地接口
- 提供全套附加核心,包括在线ECC核心
- 与目标HBM3E/3 PHY完全集成并验证
Rambus GDDR6内存控制器
Rambus GDDR6内存控制器专为性能和电源效率而设计,支持AI/ML推理的高带宽、低延迟要求。
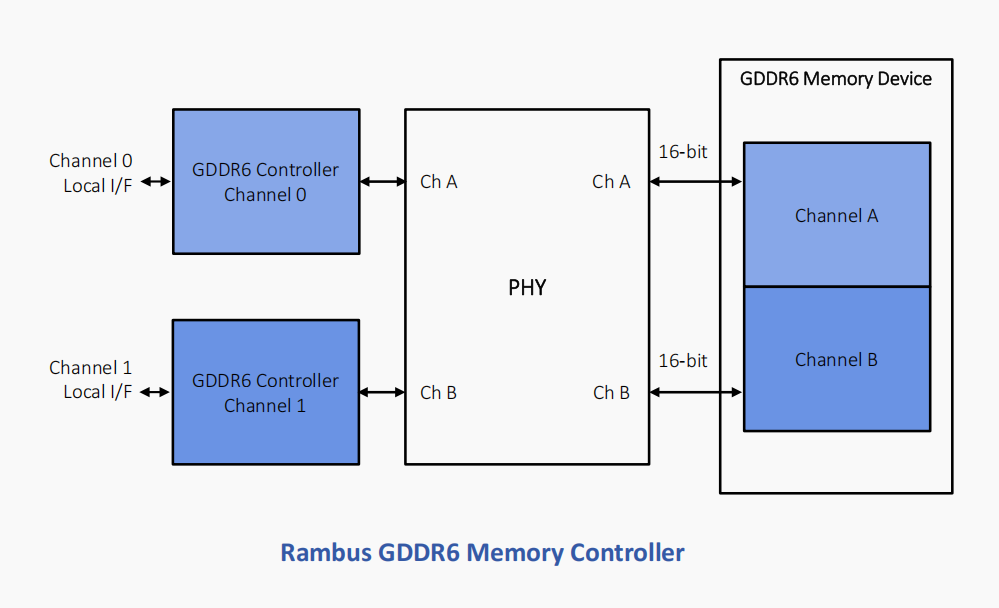
Rambus GDDR6控制器完全符合JEDEC GDDR6 JESD250C标准。它提供行业领先的每引脚24 Gb/s的速度,并支持2个通道,每个通道16位,总数据宽度为32位。在每引脚24 Gb/s的速度下,Rambus GDDR6控制器提供96 GB/s的带宽。
其他关键特性包括:
- 支持每引脚高达24 Gb/s的操作
- 一个控制器可处理两个x16 GDDR6通道,或两个控制器独立处理
- 支持x8或x16翻盖模式
- 基于队列的接口优化性能和吞吐量
- 通过预命令处理最大化内存带宽并最小化延迟
- 检测到EDC错误时自动重试事务
- 完全运行时可配置的时序参数和内存设置
- 支持自动和控制器启动的训练
- 兼容DFI(带有GDDR6扩展)
- 提供全套附加核心,包括在线ECC核心
- 支持到用户逻辑的AXI或本地接口
- 与目标GDDR6 PHY完全集成并验证
Part 5
结论
AI/ML的发展继续以闪电般的速度前进。训练能力以每年10倍的速度增长,推动着计算硬件和软件各个方面的快速改进。与此同时,AI推理正在网络边缘的特定应用硅和AI加速器中部署。
训练和推理具有独特的应用要求,可以通过定制的内存解决方案来满足,HBM3E非常适合前者,GDDR6适合后者。
设计师可以通过与Rambus合作,克服这些架构中固有的设计挑战,实现这些高性能内存的优势。Rambus提供市场领先的HBM3E/3和GDDR6内存控制器,可随时集成到AI/ML训练和推理SoC中。
资料来源:Rambus《HBM3 and GDDR6 Memory Solutions for AI》
https://go.rambus.com/l/803123/2020-03-02/wsx59/803123/1681938714dkV4H1uf/HBM3_and_GDDR6_Memory_Solutions_for_AI_wp.pdf


