 供需大厅
供需大厅
 登录/注册
登录/注册 供应商登录
供应商登录










荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。
欢迎来到荣格工业资源网!

供需大厅

登录/注册
公众号

更多资讯,关注微信公众号
小秘书

更多资讯,关注荣格小秘书
邮箱
您可以联系我们 info@ringiertrade.com

电话
您可以拨打热线
+86-21 6289-5533 x 269
建议或意见
+86-20 2885 5256
顶部

荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。



注:本文来源SemiVision,以下对原文有删减。
在 2025 年台积电北美技术论坛上,台积电全面介绍了一系列关键的先进技术发展,并深入解析了塑造半导体产业未来的主要挑战与机遇。
随着人工智能(AI)技术快速渗透到从云数据中心到边缘计算设备的各个领域,智能化正在变得无处不在。这种转型对半导体技术提出了前所未有的挑战与需求,促使从 AI 设备到云平台的整个领域,必须在先进逻辑制程上实现全面性突破。
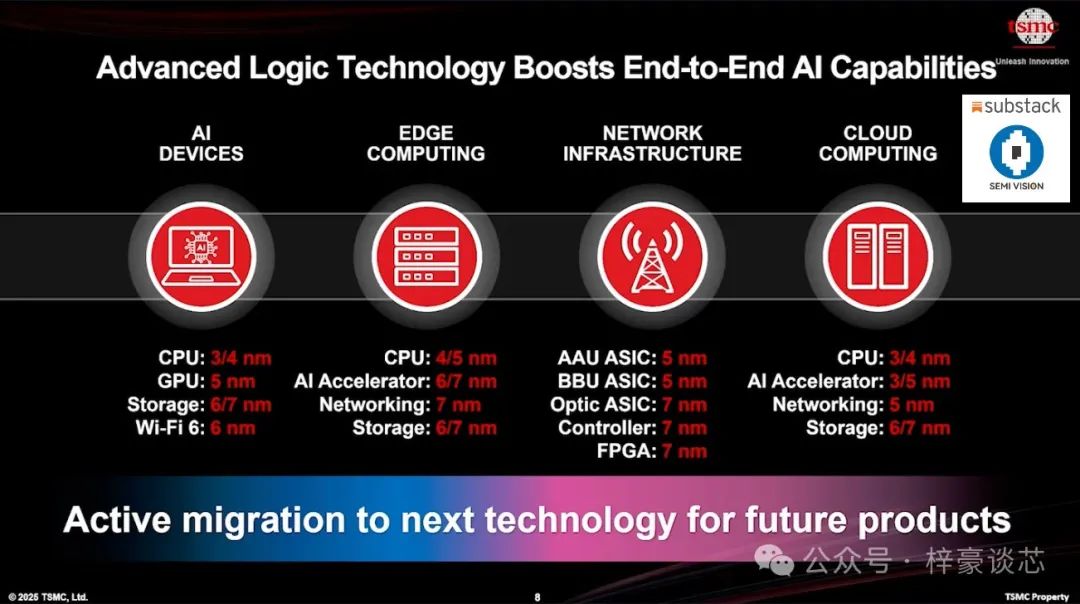
在 AI 设备领域,CPU 正在以 3nm 和 4nm 节点进行设计,GPU 正迈向 5nm,存储和 Wi-Fi 组件则朝 6nm 和 7nm 节点发展。
在边缘计算方面,AI 加速器和存储控制器主要采用 6nm/7nm 技术,而网络芯片则大多停留在 7nm 节点。
在网络基础设施领域,关键组件如主动式天线单元(AAU)、基带单元(BBU)、光学 ASIC、控制器及 FPGA,主要集中在 5nm 至 7nm 技术节点。
同时,云计算平台正在积极转向 3nm 和 4nm 节点,整合 3nm/5nm AI 加速器和 5nm 网络芯片。
总体而言,从 AI 边缘设备到云数据中心,整个 AI 计算链正迅速迁移至下一代先进半导体节点,积极采用新技术,以满足未来产品对更高性能、更低功耗和更高集成密度日益增长的需求。
• 台积电先进技术蓝图(TSMC Advanced Technology Roadmap)
台积电的先进技术蓝图(Advanced Technology Roadmap)清晰地勾画了未来制程技术演进的轨迹与方向。从 2020 年推出 N5 制程起步,随后陆续推出了 N5P 和 N7A 等强化版本,台积电在 2022 年进一步推进至 N4 节点。到了 2023 年,公司发布了 N3 制程及其衍生技术 N4P 和 N4X,并在 2024 年正式进入 N3E 和 N5A 时代。进入 2025 年,台积电计划推出 N2 以及 N3P/N3X 技术,展现出全面且积极的领导策略。

• N2、A16 与 A14 技术节点的 PPA(性能、功耗、面积)表现
展望 2026 至 2028 年,台积电将陆续推出 N2P、N3A、A16 和 N2X 节点,并最终朝向 A14 技术节点迈进,进一步巩固其在先进制造领域的领导地位。
针对主流市场领域——包括中低端移动设备、消费电子产品及通信基础设施(如基站)——台积电的蓝图显示,将从现有的 12FFC+ 和 16FFC+ 稳步推进至 N6、N4P 和 N4C 节点,未来计划进一步迁移到 N3C 技术节点。
总体来看,无论是在高端市场还是主流市场,台积电的制程技术都在快速朝向新一代节点演进,这些节点提供更高的能效与性能。尤其是 AI 加速器、数据中心服务器及高端移动设备等领域,对高密度、高性能、低功耗芯片的需求持续增长,将继续驱动半导体制程技术的积极创新与微缩发展。
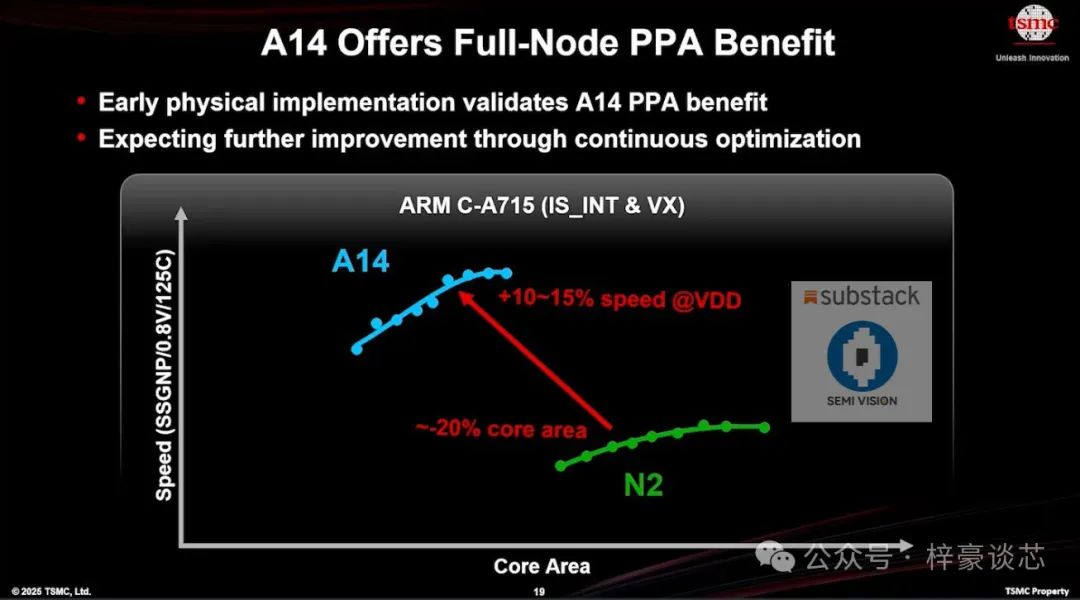
在次世代节点的验证过程中,台积电的 A14 制程通过早期的实物实现(physical implementation),成功展示了其卓越的 PPA(性能、功耗、面积)优势。与 N2 节点相比,A14 在相同工作电压下,计算速度提升了 10% 至 15%,同时核心面积缩小了约 20%。
这种在性能提升、能效优化与面积缩放方面的全面进步,不仅使芯片具备更高的计算能力,还有助于芯片小型化以及系统层级的整体功耗降低。这些改进预计将在关键应用领域,如数据中心 AI 训练加速器、高性能计算(HPC)平台以及次世代高端移动处理器中,产生直接且深远的影响,加速未来智能计算基础设施的开发与部署。
关于 N2 制程的进展,台积电强调,目前生产推进顺利,已有多个客户完成了流片(tape-out)。N2 制程中采用的奈米片(nanosheet)器件表现接近目标规格,而 256Mb SRAM 测试芯片的平均良率已超过 90%,显示出极强的工艺稳定性与成熟度。
根据台积电的路线图,N2 预计将在 2025 年下半年进入量产阶段,随后在 2026 年推出性能与能效进一步提升的增强版 N2P 节点。此外,专门针对高频运算应用的 N2X 变体预计将在 2027 年亮相,最大工作频率(Fmax)预计提升约 10%。
具体指标方面,相较于目前的 N3E 节点,N2P 在相同功耗条件下计算速度将提升约 18%,或在相同速度下功耗降低约 36%。逻辑密度(Logic Density)将提高超过 1.2 倍,整体芯片密度将提升至少 1.15 倍。
这些技术进步明确地奠定了 N2 系列技术在未来数年内的重要地位,将推动能效重大突破,并为未来 AI 与高性能计算(HPC)平台提供强大动力。
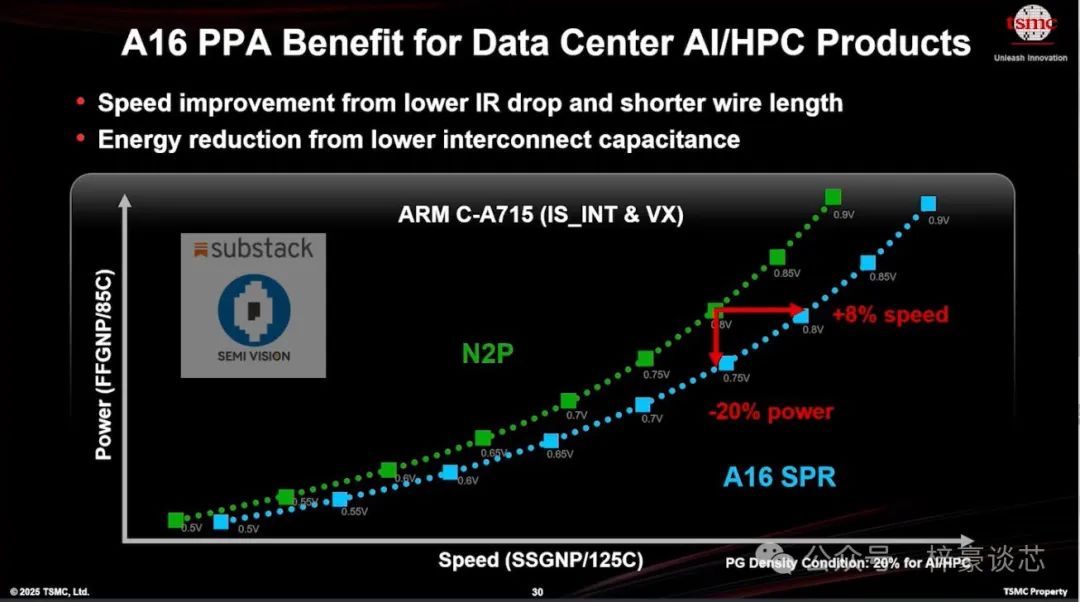
为了进一步优化数据中心 AI 和高性能计算(HPC)产品,台积电的 A16 制程平台带来了卓越的 PPA(性能、功耗、面积)提升。与 N2P 节点相比,A16 在计算速度上提高了约 8%,同时功耗降低了约 20%。
这些改进主要得益于更低的 IR 电压降损(IR Drop)和更短的互连长度,从而整体降低了互连电容(interconnect capacitance),显著提升了系统能效与计算性能。这种全面优化对于支持生成式 AI 训练工作负载和大型语言模型(LLM)推理系统尤为关键,因为这些平台需要极高的带宽、超低延迟和大规模计算资源。
因此,A16 有望成为推动下一波智能计算基础设施升级的关键赋能技术之一。
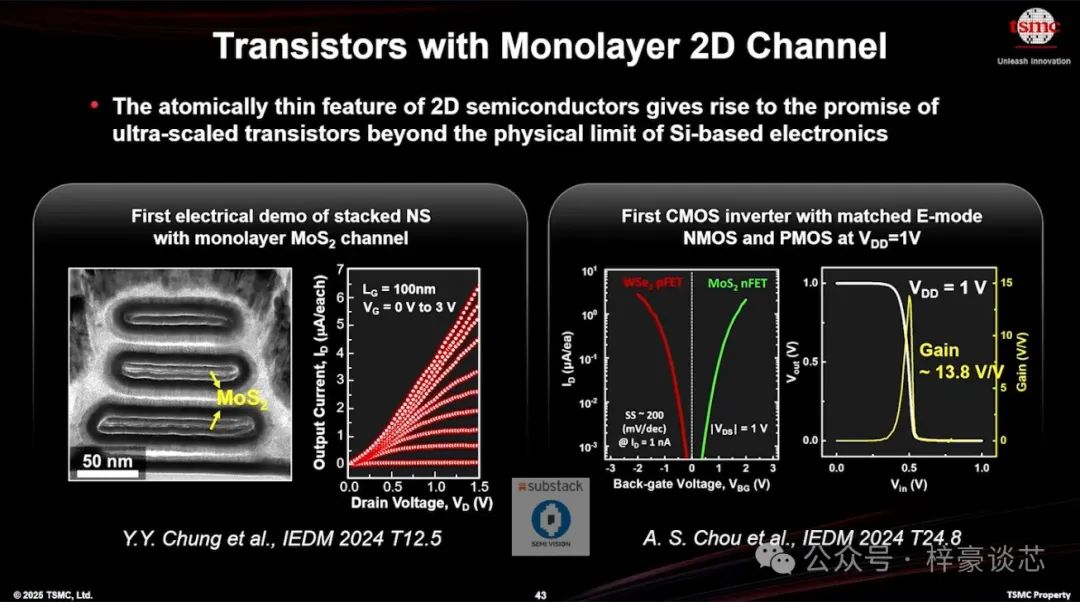
• 元器件架构展望(Device Architecture Outlook)
• CFET 与二维材料(2D Materials)的创新
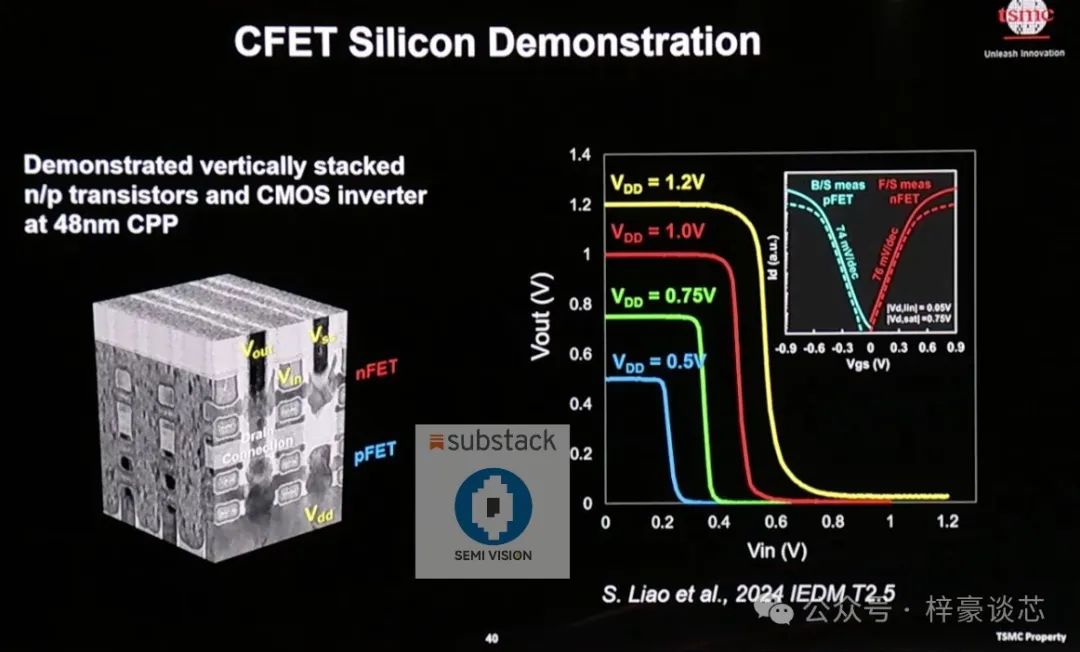
展望更远的未来,晶体管架构的演进正坚定地从 FinFET 向奈米片(Nanosheet)技术推进,并且已有明确路线图朝向 CFET(互补式场效应晶体管,Complementary FET)结构发展,预计成为主流趋势。
CFET 技术通过在单一结构中垂直堆叠 P 型与 N 型晶体管,突破了传统水平布局的限制,能够实现更高的器件密度和更短的互连长度——这对持续微缩至关重要。
随着传统硅材料逐渐接近物理极限,台积电也在积极探索**超越硅(Beyond-Silicon)**的技术,包括使用二硫族过渡金属化合物(2D TMDs),例如二硒化钨(WSe₂)和二硫化钼(MoS₂),以期在静电控制与微缩能力上超越传统硅材料。
与此同时,台积电也在进行碳纳米管(CNT)技术的研究,旨在利用其高载流子迁移率和低工作电压特性,作为新一代通道材料。
这些前瞻性的创新有望支持未来亚 1nm 节点乃至埃米(Å)级器件的发展,帮助摩尔定律(Moore’s Law)在后硅时代持续演进。
• HBM 基底(Base Die)创新
随着 AI 和高性能计算(HPC)需求持续飙升,半导体技术的演进已不再仅限于晶体管微缩,互连材料与封装架构的创新也成为推动系统级性能达到新极限的关键因素。
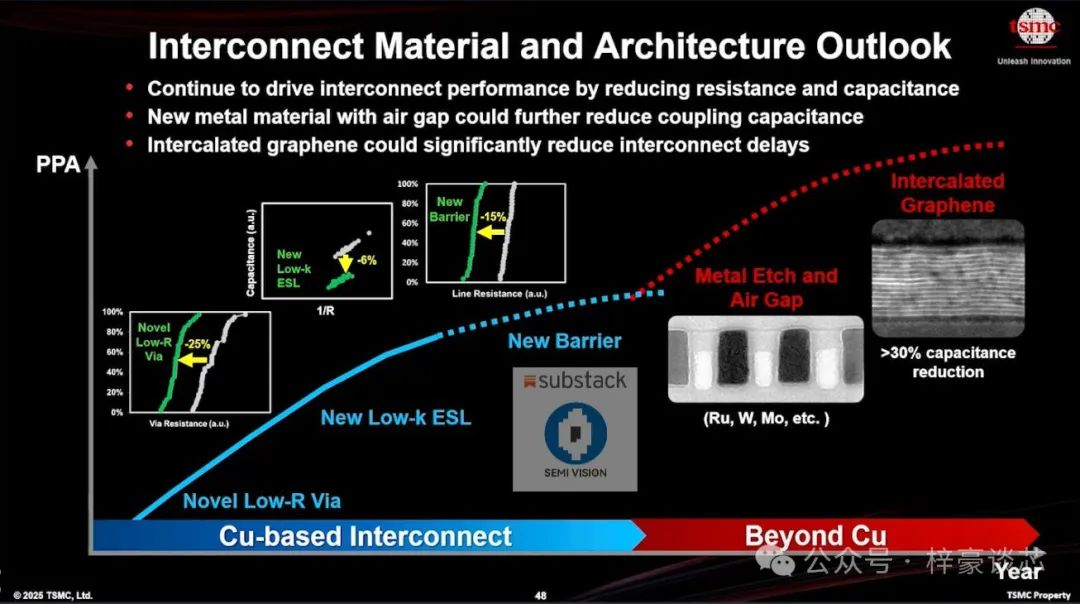
在互连材料创新领域,台积电正积极推动优化,旨在降低电阻与电容,从而进一步提升整体的 PPA(性能、功耗、面积)指标。在铜基互连时代,台积电引入了多项关键技术,包括:
• 新型低电阻通孔(Novel Low-R Via)
• 新型低介电常数材料(New Low-k ESL)
• 新型阻挡层(New Barrier)
通过这些技术,台积电实现了:
• 通孔电阻降低约 25%
• 电容降低约 6%
• 线路电阻降低约 15%
这些进步有效缓解了持续制程微缩所带来的互连延迟增加与功耗上升的问题。
展望未来的 Beyond-Cu 时代,台积电正推进一系列新技术,包括:
• 金属蚀刻(Metal Etch)结合空气间隙结构(Air Gap)
• 采用新型导电材料,如钌(Ru)、钨(W)与钼(Mo)
以进一步降低耦合电容(Coupling Capacitance)。此外,台积电也在积极开发插层石墨烯结构(Intercalated Graphene),预计能带来超过 30% 的电容降低。
这些创新有望显著降低互连延迟、提升信号完整性(Signal Integrity),为 1nm 以下技术节点的终极微缩提供关键材料支撑。
在系统整合方面,为了应对 AI 计算日益增长的高功耗需求,台积电开发了新一代 HPC/AI 系统整合技术平台。该平台将最先进的 FinFET 逻辑制程、高频宽存储器(HBM)堆叠、硅光子(SiPh)光学引擎与高效电源传输解决方案,整合到一个高度集成且模块化的计算架构中。
这一架构基于大面积、高密度基板构建,紧密集成了:
• 主动硅芯片(Active Die)
• 局部硅互连(Local Silicon Interconnect, LSI)
• 嵌入式电压调节器(Embedded Voltage Regulator, IVR)
• 深槽电容(Deep Trench Capacitor, DTC)
通过这种整合,实现了高速、低延迟的计算互连,同时显著提升了电源完整性(Power Integrity)与热管理能力。
在数据传输方面,该平台利用硅光子模块(Silicon Photonics Module),直接在封装层级集成光学信号传输,相比传统铜互连,大幅提升了频宽密度,并显著降低了功耗。
这一解决方案特别适用于支持超大规模生成式 AI 模型与超大规模数据中心内部高性能通信需求,为下一代智能计算基础设施提供了坚实的技术支撑。


• 先进封装技术(Advanced Package)的创新
为了应对内存与计算单元之间日益严峻的互连挑战,台积电持续推进 HBM 基底(Base-Die)技术的创新与发展。传统的 HBM 架构通常是将 DRAM 晶片直接堆叠在逻辑层(SoC)之上,但随着数据访问需求的不断增长,这种方式已经遭遇到频宽瓶颈与系统性能限制。
对此,台积电在新一代平台中,将 HBM Base-Die 作为独立的中介层,通过大面积中介层(interposer)与 SoC 连接。这样的设计可以在不牺牲逻辑微缩与性能优化的前提下,实现更灵活的多层次内存堆叠,显著提升数据访问效率与整体系统频宽。
针对当前的 HBM4 世代,台积电采用了 N12 制程技术来制造 Base-Die,相较于以往设计,功耗降低超过 40%。展望未来,台积电计划迁移至 N3 制程,预计在 2026 年后进入量产,届时将为次世代 HBM/AI 系统带来更高的集成密度与更优异的能效表现。
就 HBM Base-Die 技术演进路线而言,台积电已经制定出明确的转型路径:
• N12 制程将支援即将量产的 HBM4,带来第一波超低功耗优势;
• N3 制程将作为未来 HBM5 及更高世代产品的技术基础,以支撑更高堆叠层数与更大频宽需求。
这一策略不仅展现了台积电在先进逻辑制造领域的领导地位,同时也涵盖了内存互连、先进封装及系统级整合(SiP)等领域,建立起从材料、器件到系统的全面竞争优势,为未来 AI 计算、超大规模数据中心以及次世代高性能存储解决方案奠定了坚实且可扩展的技术基础。


