 供需大厅
供需大厅
 登录/注册
登录/注册 供应商登录
供应商登录










荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。
欢迎来到荣格工业资源网!

供需大厅

登录/注册
公众号

更多资讯,关注微信公众号
小秘书

更多资讯,关注荣格小秘书
邮箱
您可以联系我们 info@ringiertrade.com

电话
您可以拨打热线
+86-21 6289-5533 x 269
建议或意见
+86-20 2885 5256
顶部

荣格工业资源APP
了解工业圈,从荣格工业资源APP开始。




图片来源 / nextplatform
来源 / nextplatform;荣格电子芯片翻译
作者 / Timothy Prickett Morgan
在 Hot Chips 2024 大会上,IBM 负责微处理器设计的杰出工程师 Chris Berry 介绍了将嵌入下一代大型机处理器的 AI 加速,代号为“Telum II”,可能作为 z17 销售,继在 Hot Chips 2021 上亮相的“Telum”处理器之后并被称为 Z16。
Berry 披露了有关 Telum II 芯片的一些细节,包括其片上 DPU,还透露 IBM 确实将 AI 加速单元或 AIU 商业化,该单元由 IBM 研究院多年来开发。
Part 1
Telum II z17 处理器
Telum II 处理器有 430 亿个晶体管,与 Telum 芯片一样,它有 8 个非常胖的内核来执行后台系统中常见的卡冲击处理,这代表了数据中心的第一波计算浪潮。Telum z16 处理器在 530 mm 2 中具有 225 亿个晶体管,并采用三星的 7 纳米工艺实现。
凭借 Telum II,IBM 的晶体管数量几乎翻了一番,达到 430 亿个,并将芯片面积增加到 600 mm2,这要归功于三星 5 纳米工艺(准确地说是 5HPP)的缩小。许多额外的晶体管将用于更强大的 L2 缓存,但其中一些被分配给片上 DPU 以及更大容量的片上 AI 加速器,我们预计这是从 AIU 衍生的电路部分。

DPU 位于左侧的中间,并且在芯片中有一些死区,因为正如 Berry 所说,DPU 设计比 IBM 预期的“小一点”。在我们看来,它只占用 1.6 个内核的空间,而不是 IBM 计划的两个内核。看起来 IBM 发现它可以牺牲两个 z17 内核,并将它们换成一个集成的 DPU,以加速和简化 I/O,并提高计算综合体的整体有效性能,即使内核数量保持不变,并且与 z16 内核相比,时钟速度仅提高了约 10% 至 5.5 GHz。得益于 IPC 和其他改进, 与 Z20 相比,每个插槽的性能提高了 16%。
与 z16 一样,z17 取消了早期 System z 处理器中常用的 L3 和 L4 缓存,L2 缓存块可以根据软件需要将自己呈现为共享的 L3 或 L4 缓存。看起来进入 Telum II 处理器的增加的晶体管数量中有一大块进入了缓存。Telum II 有 10 个 L2 缓存,每个缓存重 36 MB,而两年前的原始 Telum 芯片中有 8 个 32 MB 缓存。
Telum II 具有 360 MB 的虚拟 L3 缓存,比 Telum 芯片上的 240 MB 虚拟 L3 缓存增加了 50%。Telum II 上的 2.88 GB 虚拟 L4 缓存比第一代 Telum 芯片上的 L4 缓存大 40%。虚拟 L4 缓存可能是系统中 DDR5 主内存的一个分区,在四插槽抽屉中最大为 16 TB,每个插槽有两个 Telum II 芯片。(与 z60 抽屉相比,主内存容量增加了 16%。此主内存实现 OpenCAPI 内存接口,就像 z16 和 Power10 处理器一样。据推测,它将使用刚刚宣布的 DDR5 内存芯片作为 Power10 处理器的升级,而不是 z4 中使用的 DDR16 内存,最初用于 Power10 系统。)
z16 和 z17 系统从 1 个抽屉扩展到 4 个抽屉,其中包括 16 个插槽、32 个小芯片和 256 个内核,具有 64 TB 的主内存。该系统还具有 192 个 PCI-Express 5.0 插槽,这些插槽封装在十几个 I/O 扩展抽屉中,每个抽屉有 16 个插槽。(这些插槽是插入磁盘驱动器、闪存驱动器、加密处理器或 AI 的 Spyre 加速器卡的位置。)
Part 2
数据处理单元兜兜转转
“大型机处理大量数据,”Berry 在 Hot Chips 的演讲中解释道。“一台完全配置的 IBM z16 每天能够处理 250 亿笔加密交易。这比 Google 搜索、Facebook 帖子和推文的总和还要多。这种规模需要的 I/O 能力远远超出了典型计算系统所能提供的能力。它需要自定义 I/O 协议来最大限度地减少延迟,支持数千个操作系统实例的虚拟化,并且可以在任何时间点处理数以万计的未完成 I/O 请求。
“因此,我们决定利用 DPU 来实现这些自定义 I/O 协议,并且考虑到处理器和 I/O 子系统之间的所有通信,我们决定将 DPU 直接放在处理器芯片上,而不仅仅是将 DPU 连接到 PCI 总线后面。我们将其连贯地连接到处理器 SMP 结构中,并通过将 DPU 放在 PCI 接口的处理器侧,并实现 DPU 与运行主要企业工作负载的主处理器的一致通信,为其提供自己的 L2 缓存。我们最大限度地减少了通信延迟,提高了性能和电源效率,使整个系统的 I/O 管理功耗降低了 70% 以上。”
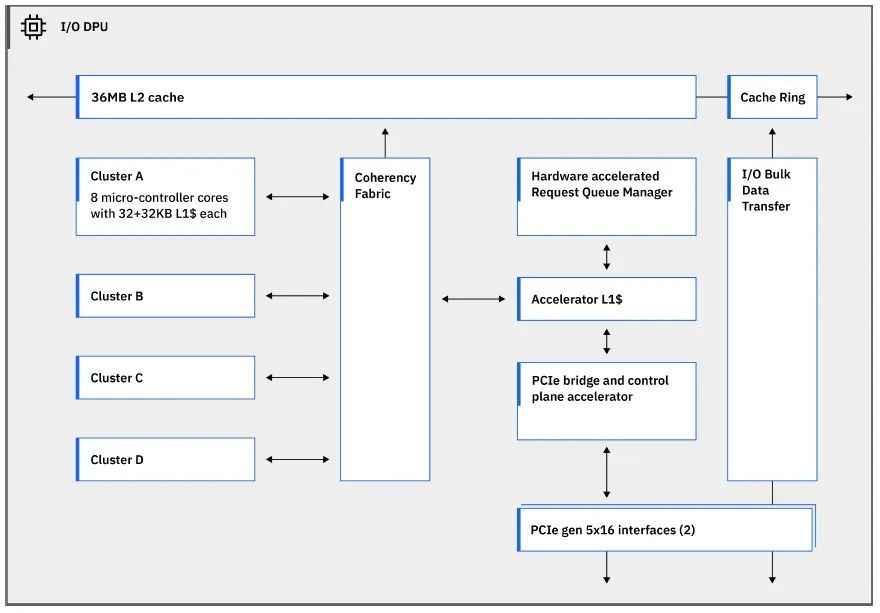
Telum II DPU 有四个集群,每个集群有四个内核,每个内核都有 32KB 的 L1 数据缓存和 32KB 的 L1 指令缓存。没有给出这些内核的详细信息,但它们可能是 IBM 自己的 Power 内核(可能是轻量级内核)或 Arm 内核。(我们认为是前者而不是后者。DPU 连接到其中一个 36 MB L2 缓存分段,这意味着有一个备用的 36 MB L2 缓存未附加到任何特定内核或 DPU。DPU 有一对 PCI-Express 5.0 x16 接口,这些接口链接到同样位于 Telum II 芯片上的一对 PCI-Express 5.0 控制器,并链接到这些 I/O 扩展抽屉。
片上 AI 加速器位于芯片的左下角,面积与其中一个 z17 内核大致相同,但它被压平了。我们假设该架构是 AI 加速器的改进版本,它嵌入在第一代 Telum 芯片的同一位置。Berry 表示,IBM 在 Telum 芯片的第一代 AI 加速器支持的现有 FP16 中添加了 INT8 数据类型,并且还允许片上 AI 加速器在 z17 系统中的所有 Telum II 芯片之间共享,这些互连也通过 XBus 和 Abus NUMA 互连实现,以创建共享内存系统。
Telum II 上的片上 AI 加速器具有每秒 24 teraops (TOPS) 的性能;我们没有三年前 Telum AI 加速器的评级。客户现在可以在每个 z17 抽屉中使用 192 TOPS,在整个 z17 系统中可以访问 768 TOPS。
但它并没有就此结束。现在 Spyre 已经商业化,客户可以在这些 I/O 抽屉中加载 Spyre 加速器,并带来更多的 AI 功能。
Part 3
不断扩大的 Spyre
Spyre 芯片采用三星 5 纳米工艺 (5LPE) 的低功耗变体实现,在 330 mm2 的面积上具有 260 亿个晶体管。
IBM 作为研究项目所做的原始 AIU 以及我们两年前谈到的它有 32 个内核,这些内核与 Telum 处理器中的 AI 加速器非常相似,其中 32 个内核可用于良率目的,全部采用三星 5 纳米工艺和 2300 万个晶体管。Spyre 似乎是这款 AIU 芯片的调整版本,每个内核有 32 个内核和 2 MB 的暂存器内存。
以下是 Spyre 核心的框图:
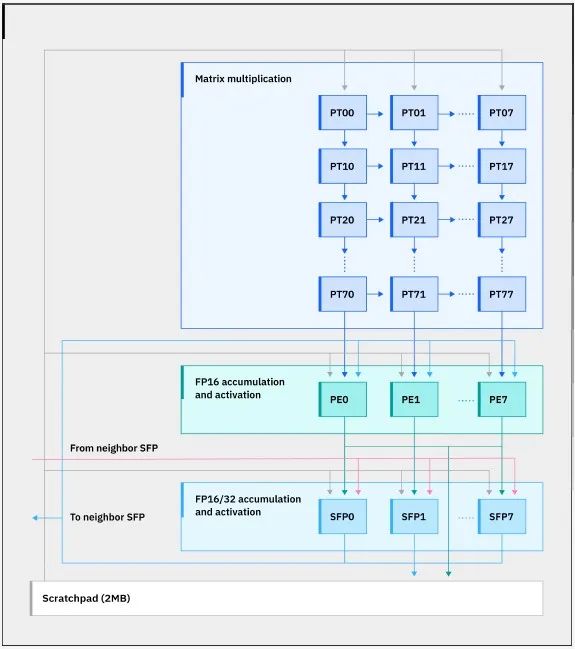
在 Spyre 芯片上,有一个 32 字节的双向环连接 32 个内核——嗯,我们认为是 34 个内核,只有 32 个处于活动状态的内核,而一个单独的 128 字节环连接与内核相关的暂存器内存。内核支持 INT4、INT8、FP8 和 FP16 数据类型。
以下是 Spyre 加速卡的外观:

Spyre 卡在 8 个库中实现了 128 GB 的 LPDDR5 内存——比原始 AIU 上实现的 48 GB 要多得多——并在 300 瓦的包络内提供超过 16 TOPS(大概是 FP16 分辨率)。Spyre 卡插入 PCI-Express 5.0 x16 插槽。LPDDR5 内存连接到 Scratchpad 内存环,并向该环提供 200 GB/s 的内存带宽。
如果您在 I/O 抽屉中将 8 个 Spyre 卡组合在一起(这是 IBM 建议的最大值),则会创建一个虚拟 Spyre 卡,该卡具有 1 TB 的内存和 1.6 TB/秒的内存带宽,用于运行 AI 模型,总性能超过 3 petaops(大概是 FP16 分辨率)。有了 10 个这样的抽屉,您谈论的是 10 TB 的内存和 16 TB/秒的聚合带宽,以及 30 petaops 的 AI 动力。

这绝对足以让 IBM 大型机商店在其应用程序和数据库以及 z17 综合体的“主机”的安全边界内进行一些相当严肃的 AI。
Spyre 卡将于明年发货,大概 z17 主机也发货时。Berry 没有提供确切的日期,但确实表示它现在处于技术预览阶段,这意味着选定的客户现在可以亲身体验它。
最后一件事。Telum II 处理器或 Spyre 加速器中的加速器绝对没有将其与 IBM System z 大型机专门联系在一起。事实上,使编程工具和编译器的相同方法使片上 AI 加速器和外部 Spyre 加速器看起来像 z17 处理器的原生指令,例如,IBM 未来的 Power11 处理器也可以完成,该处理器也将于明年推出。
原文链接:
https://www.nextplatform.com/2024/08/27/ibm-shows-off-next-gen-ai-acceleration-on-chip-dpu-for-big-iron/
*声明:本文系原作者创作。文章内容系其个人观点,我方转载仅为分享与讨论,不代表我方赞成或认同,如有异议,请联系后台。



